
アテンション機構(3/4)変形例の検討
はぐれ弁理士 PA Tora-O です。前回(第2回)では、“Seq2Seq with Attention” について説明しました。改めて復習されたい方は、こちらのリンクから確認をお願いします。今回(第3回)は、“Seq2Seq with Attention” の様々なバリエーションについて検討していきます。
第1変形例
前回では、隠れ状態行列{H1}のすべての要素、すなわち、S個の隠れ状態ベクトルh1を使ってコンテキストベクトルc(t) を計算する、と説明しました。この計算モデルは、注意の対象範囲が全体的にわたるという意味で、グローバルアテンションモデル(Global Attention Model)と呼ばれています。
ところが、このモデルでは、Sの値が増加するにつれて計算量が増加するという問題が起こり得ます。その解決策として、注意の対象範囲を局所的に絞ることで計算コストを削減する手法が考えられます。本論文では、この計算モデルは、ローカルアテンションモデル(Local Attention Model)と呼ばれています。
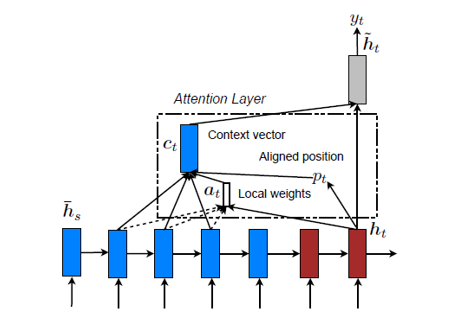
出展:Effective Approaches to Attention-based Neural Machine Translation
図1のモデルでは、隠れ状態ベクトルh2(t) に対応する基準位置(P番目)を求め、この位置に近い(P-D)~(P+D)番目の隠れ状態ベクトルh1のみを用いて、注目度a(t) およびコンテキストベクトルc(t) を計算します。例えば、再帰演算の回数(=t)をPとしてもよいし、ベクトル類似度が最大となる位置をPとしても構いません。
第2変形例
前回では、再帰演算層が1層である構成例を説明しましたが、これが2層以上であるデコーダにも適用されます。
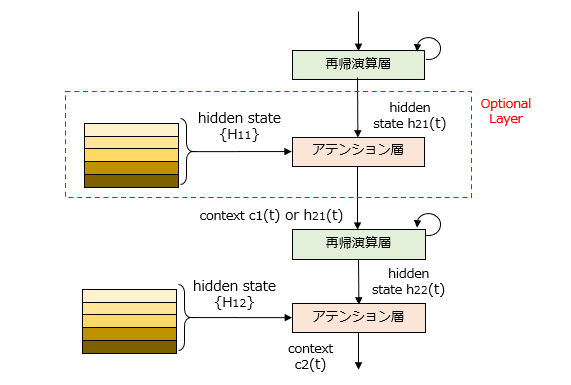
図2のモデルでは、2層の再帰演算層を含んで構成されるエンコーダ/デコーダを想定しています。デコーダ側の1番目のアテンション層にはエンコーダ側の隠れ状態行列{H11}が供給されるとともに、デコーダ側の2番目のアテンション層にはエンコーダ側の隠れ状態行列{H22}が供給されます。ここで、{H11}、{H12}は、エンコーダ側の1、2番目の再帰演算層から出力される隠れ状態行列です。
このように、アテンション機構を再帰演算層ごとに実装してもよいですし、さらに他のバリエーションも考えられます。例えば、[1]1番目のアテンション層を省略する構成や、[2]隠れ状態行列{H11}の出力を省略する代わりに、1番目のアテンション層にも{H12}を供給する構成、などが挙げられます。
第3変形例
前回では、アテンション層がL次元のコンテキストベクトルc(t) を出力する、と説明しました。これに代えて、図3に示すように、2つのベクトルc(t) 、h2(t) を連結(Concatenate)して2・L次元のベクトルを出力しても構いません。
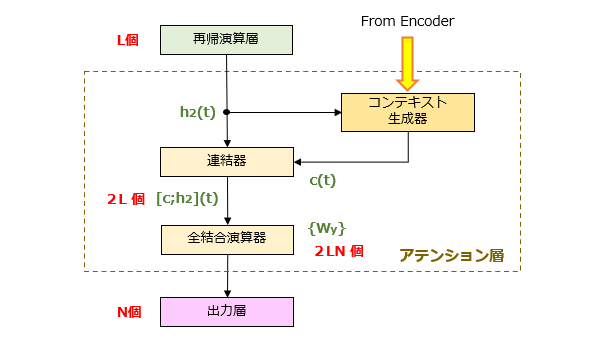
まとめ
以上のように、アテンション機構は、その内部構造のみならずデコーダへの組み込み構造も色々変更できる点で、技術的特徴を捉えにくい発明であるとも言えます。果たして、これらのバリエーションをすべて網羅するクレーム表現は可能でしょうか? 次回までの宿題としておきます。
以上、今回(第3回)は、アテンション機構の変形例について検討しました。テーマ最終回(第4回)は、過去3回分を総括すべく、一連の発明ストーリーを完成させてみます。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。