
FCN (2/4) 実施例の説明
はぐれ弁理士 PA Tora-O です。前回(第1回)では、FCNの概要について説明しました。改めて復習されたい方は、こちらのリンクから確認をお願いします。今回(第2回)は、FCNの実施例について説明します。
ネットワーク構造
まず、FCNのネットワーク構造は、次に示す図1の通りです。
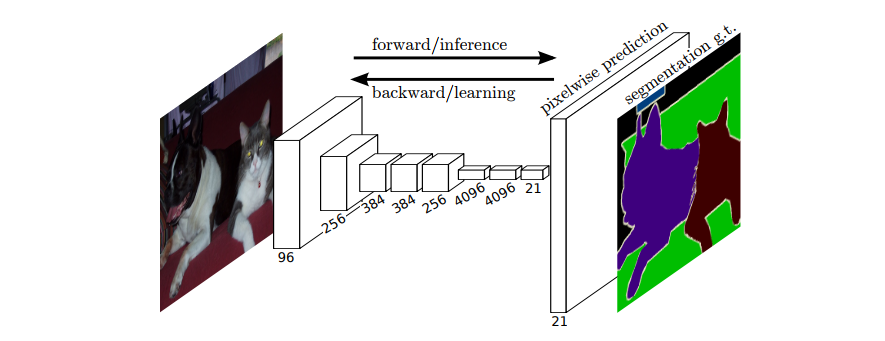
出展:Fully Convolutional Networks for Semantic Segmentation
本モデルの訴求点は、「全結合層」=FC層(Fully Connected Layers)を省略したことにあり、そのモデル名である「全畳み込みネットワーク」=FCN(Fully Convolutional Networks)に強く体現されています。FCNの前段部には、AlexNet、VGG、GoogLeNet を含む様々な畳み込み演算モデルが用いられます。つまり、後段部の “pixelwise prediction” に工夫があると言えそうです。
Pixelwise prediction
続いて、FCNの後段部(pixelwise prediction)について説明します。以下、図示の簡素化のため、カーネルサイズが2×2のプーリング処理を行う5つのプーリング層P1~P5を表記しています。本論文では、[1]FCN-32s、[2]FCN-16s、[3]FCN-8s、の3種類が提案されています。
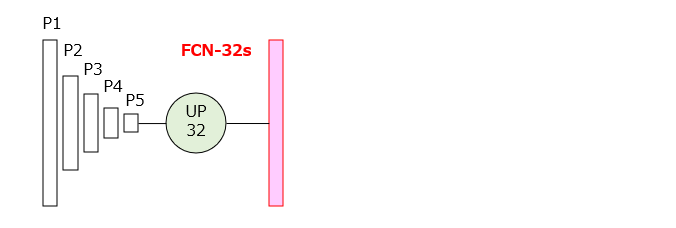
図2Aは、FCN-32sの層構成を示しています。図中の「UP32」は、カーネルサイズが32×32のアンプーリング(あるいは、アップサンプリング)を行う演算子を示しています。FCN-32sでは、[1]P5層の出力マップを32倍に拡大することで、P1層と同じサイズのヒートマップ、すなわち画素毎のセグメンテーション結果が得られます。
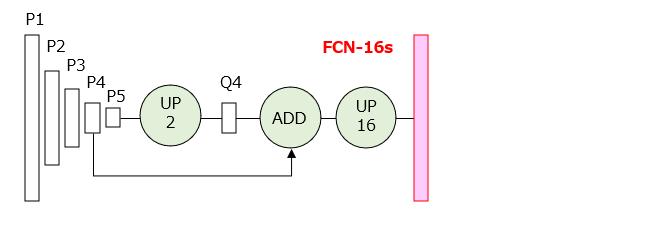
図2Bは、FCN-16sの層構成を示しています。図中の「UP2」、「UP16」は、カーネルサイズが2×2、16×16のアンプーリングを行う演算子をそれぞれ示しています。FCN-16sでは、[1]P5層の出力マップを2倍に拡大し、[2]P4層の出力マップを画素毎に加算し、[3]16倍に拡大することで、画素毎のセグメンテーション結果が得られます。
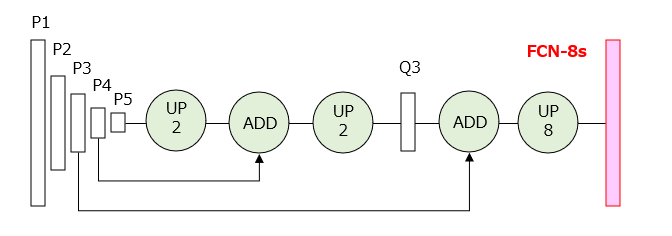
図2Cは、FCN-8sの層構成を示しています。図中の「UP8」は、カーネルサイズが8×8のアンプーリングを行う演算子を示しています。FCN-16sでは、[1]P5層の出力マップを2倍に拡大し、[2]P4層の出力マップを画素毎に加算し、[3]2倍に拡大し、[4]P3層の出力マップを画素毎に加算し、[5]8倍に拡大することで、画素毎のセグメンテーション結果が得られます。
そして、大体察しが付くと思いますが、32s<16s<8sの順で、検出精度が高くなっています。
以上、今回(第2回)は、FCNの実施例について説明しました。次回(第3回)は、FCNとほぼ同時期に発表され、しかもFCNに類似する技術であるU-Netについて説明します。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。