
RetinaNet (2/4) 実施例の説明
はぐれ弁理士 PA Tora-O です。前回(第1回)では、RetinaNet の概要について説明しました。改めて復習されたい方は、こちらのリンクから確認をお願いします。今回(第2回)は、RetinaNet の実施例について説明します。
ネットワーク構造
まず、RetinaNet のネットワーク構造は、次に示す図1の通りです。
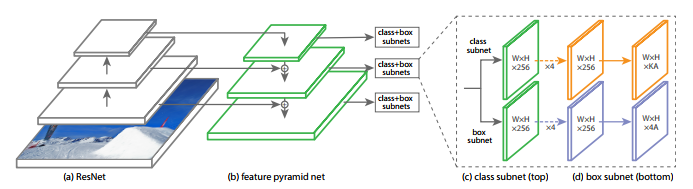
出展:Focal Loss for Dense Object Detection
この図から理解されるように、RetinaNet は、FPN(Feature Pyramid Network)を One-Stage Detector に実装したものと言えそうです。なお、FPNの概要については、次の記事が参考になります。
FPN (2/4) 実施例の説明
FPN (3/4) 特許性の検討
目的関数の損失項
次に、RetinaNet の目的関数、より詳しくは損失項(Loss)について説明します。この説明に先立ち、従来型の交差エントロピー(Cross Entropy)について触れておきます。交差エントロピーCEは、次の数式1に従って算出されます。
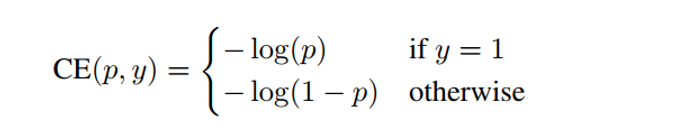
ここで、yは教示値(0 or 1)、pは確率([0,1])にそれぞれ相当します。教示値は、例えば、(1,0,0,‥‥,0)のようなN個のベクトル成分を有する One-hot Vector です。
これに対して、RetinaNet では、交差エントロピーに代わる損失項として、フォーカルロス(Focal Loss)が提案されました。フォーカルロスFLは、次の数式2に従って算出されます。
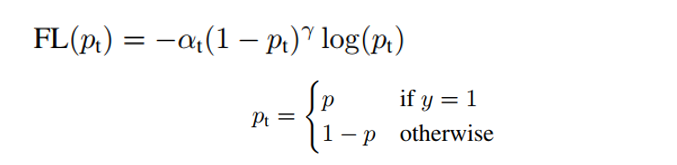
このように、フォーカルロスは、交差エントロピーに対して、α・(1-p)γ を乗算したものです。重み付け係数αと冪数γは、それぞれハイパーパラメータです。γを変化させた場合のフォーカルロスFLの関数形状を図2に示します。
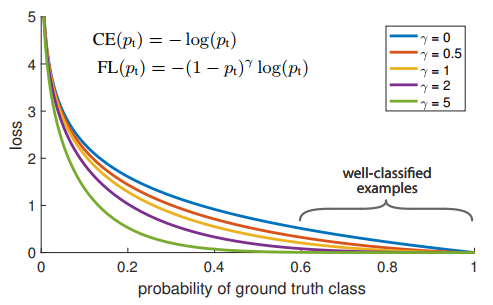
出展:Focal Loss for Dense Object Detection
FLは、γの値にかかわらず、2点(0,∞)、(1,0)を通る曲線です。γ=0の場合、FLは、CEに一致します。また、γの値が大きくなるにつれて、FLがδ関数に近づいていきます。本論文では、実験的には、γ=2が概ね最適値であると述べられています。
以上、今回(第2回)は、RetinaNet の実施例について説明しました。このように、RetinaNet の特徴事項については理解できるのですが、フォーカルロスの導入によって検出精度が向上する、という因果関係が容易にイメージしにくいと思われます。そこで、次回(第3回)は、そのメカニズムについて概略的に解説します。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。