
Seq2Seq(3/4)実施例の説明&考察
はぐれ弁理士 PA Tora-O です。前回(第2回)では、Seq2Seq の前提知識として、再帰型ニューラルネットワーク(RNN)の概要について説明しました。改めて復習されたい方は、こちらのリンクから確認をお願いします。今回(第3回)は、Seq2Seq の実施例を説明するとともに、本発明のポイントを軽く考察してみます。
問題の設定
Seq2Seq では、例えば、英語をドイツ語に翻訳する翻訳問題について取り組みます(図1)。
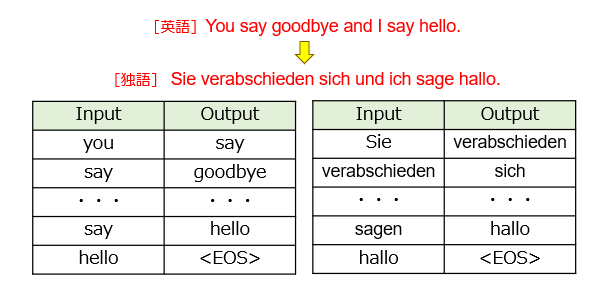
本図の例では、偶然にも単語数が一致していますが、文章の内容によって単語の構成数が異なる場合があります。また、英語やドイツ語では「SVO語順」を採用する一方、日本語では「SOV語順」を採用するなど、言語の種類によって文章の仕組みが異なる場合もあります。
ネットワーク構造
続いて、Seq2Seqモデルのネットワーク構造を図2に示します。
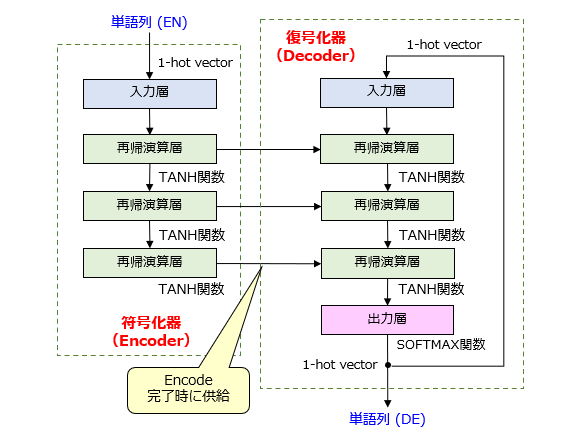
このモデルの主な特徴は、2種類のRNNが直列的に接続されており、前段のRNNが符号化器(エンコーダ;Encoder)、後段のRNNが復号化器(デコーダ;Decoder)としてそれぞれ機能する点にあります。
エンコーダは、翻訳前の単語列(英文)を構成する英単語を順番に入力しながら、隠れ状態ベクトルの作成・更新を繰り返します。「EOS」の検出に伴って英文の入力が終了すると、エンコーダは、最後に更新された隠れ状態ベクトルを、英文に関する特徴ベクトルとして出力します。このように、エンコーダは、隠れ状態ベクトルを計算すればよいため、出力層周りの演算は不要です。Seq2Seqモデルの概略図において、エンコーダ部分の出力層が省略されているのはその為です。
デコーダは、エンコーダから供給された特徴ベクトルを基に、翻訳後の単語列(独文)を構成する独単語の出力を繰り返します。特徴ベクトルが再帰演算層に直接入力されると、デコーダは、[1]1番目のラベル群(確率分布)の出力、[2]1番目の独単語の決定、[3]1番目の独単語の入力(フィードバック)、[4]2番目のラベル群の出力、[5]2番目の独単語の決定、・・・を順次繰り返します。
技術的にはやや厳密性を欠くのですが、(ⅰ)エンコーダ内で隠れ状態ベクトルが更新される度に符号化が完了した英単語に対応する英語情報が順次追加され、(ⅱ)デコーダ内で隠れ状態ベクトルが更新される度に復号化が完了した独単語に対応する英語情報が順次削除される、と理解すれば十分でしょう。このように捉えることで、複数の言語間において単語の構成数や文章の仕組みが相違する場合であっても、このような相違が Seq2seq モデル内で吸収されることが何となく説明できそうです。
ちなみに、このモデルにおける学習パラメータの更新手法として、BPTT(Backpropagation Through Time)が用いられます。今回の検討では説明を省きますが、もし興味があればネット検索などで調べてみてください。
発明ポイントの特定
続いて、Seq2Seq モデルの発明ポイントについて検討します。まず、図2のネットワーク構造に着目すると、例えば次のようなクレームが完成するでしょう。
第1の再帰型ニューラルネットワークと、第2の再帰型ニューラルネットワークを直列接続してなる単語列変換器。
この記載でも別に構わないですが、構成・作用・効果の関係を一切考慮しないクレームを作ることは、AI弁理士としてやや不満です。折角の検討の機会なので、エンコーダ部分&デコーダ部分の両方の特徴事項に関するクレームを検討したいです。
以上、今回(第3回)は、Seq2Seq の実施例を説明しました。テーマ最終回(第4回)は、過去3回分を総括すべく、一連の発明ストーリーを完成させてみます。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。