
StackGAN(2/4)実施例の説明
はぐれ弁理士 PA Tora-O です。前回(第1回)では、StackGAN の概要について説明しました。改めて復習されたい方は、こちらのリンクから確認をお願いします。今回(第2回)は、StackGAN の実施例について説明します。
システム構成
まず、StackGAN のシステム構成について、図1を参照しながら説明します。
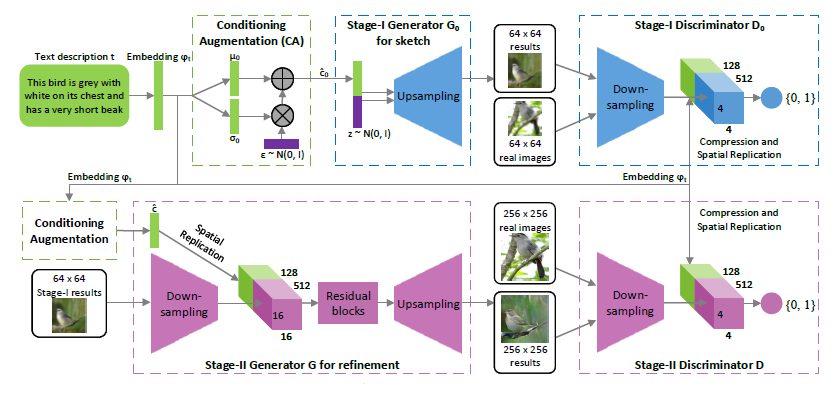
出展:StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
StackGAN は、2系統の並べられたGAN(two stacked GANs)で構成されます。上段の Stage-ⅠGAN は、テキスト文章を「低」解像度画像(Low-Resolution Images)に変換する生成ネットワークです。一方、下段の Stage-ⅡGAN は、「低」解像度画像を「高」解像度画像(High-Resolution Images)に変換する生成ネットワークです。
動作の説明
続いて、StackGAN の動作について説明します。図1は、とても良く纏まっていて説明にそのまま使えそうです。しかし、今回は、各工程を視覚的に理解できるように、図2および図3を新たに作成しました。そのため、図1に示す構成(ブロック)の一部をあえて省略しています。
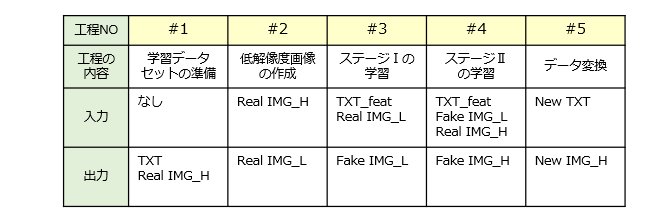
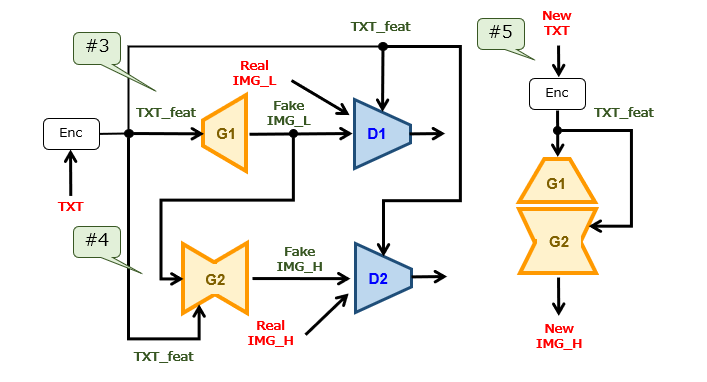
第1工程
まず、StackGAN の学習に用いる学習データセットを準備します。具体的には、テキスト文章(TXT)と、真正の高解像度画像(Real IMG_H)のペアを準備します。
第2工程
次に、真正の高解像度画像(Real IMG_H)に対して画像処理を施し、真正の低解像度画像(Real IMG_L)を生成します。この画像処理は、例えば、平均プーリング(Average Pooling)、画像間引き(Image Thinning)などが挙げられます。
第3工程
次に、Stage-ⅠGANに対する学習処理を行います。生成器G1は、テキスト特徴量(TXT_feat)を入力し、偽の低解像度画像(Fake IMG_L)を出力します。弁別器D1は、真正又は偽の低解像度画像(Real/Fake IMG_L)を入力し、画像の弁別結果を出力します。ここで、テキスト特徴量は、元のテキスト文章をエンコーダ(例えば、RNN)に投入することで得られる特徴ベクトルです。
第4工程
次に、Stage-ⅡGAN に対する学習処理を行います。生成器G2は、偽の低解像度画像(Fake IMG_L)及びテキスト特徴量(TXT_feat)を入力し、偽の高解像度画像(Fake IMG_H)を出力します。弁別器D2は、真正又は偽の高解像度画像(Real/Fake IMG_H)を入力し、画像の弁別結果を出力します。
第5工程
最後に、学習済みの生成器G1,G2を用いて、任意のテキスト(New TXT)から高解像度画像(New IMG_H)を生成します。
以上、今回(第2回)は、StackGAN の実施例について説明しました。次回(第3回)は、本発明のポイントについて考察してみます。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。