
StackGAN(3/4)本発明のポイント
はぐれ弁理士 PA Tora-O です。前回(第2回)では、StackGAN の実施例について説明しました。改めて復習されたい方は、こちらのリンクから確認をお願いします。今回(第3回)は、本発明のポイントについて考察します。
従来技術
まずは、StackGAN との比較対象である従来技術(Prior Art)を明示しておきます。ここでは、説明を省略しますが、必要に応じて下記の記事を参照してください。
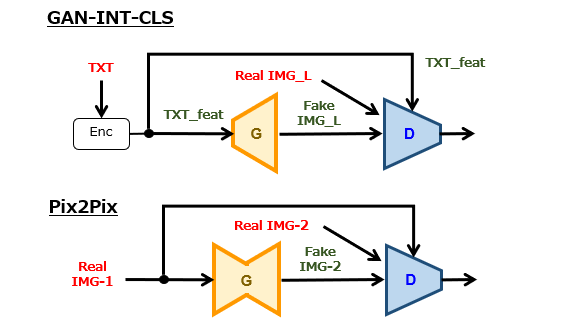
[1]GAN-INT-CLS 参考記事:StackGAN(1/4)発明の概要
[2]Pix2Pix 参考記事:Pix2Pix(2/4)実施例の説明
検討その1(Stage-Ⅱ GAN)
前回(第2回)の図1~図3から理解されるように、Stage-Ⅰ GAN は、GAN-INT-CLS と基本的には同一のネットワーク構造である、と捉えても問題ありません。そうすると、消去法の発想によって、StackGAN の特徴は、Stage-Ⅱ GAN のネットワーク構造にあると考えることができます。
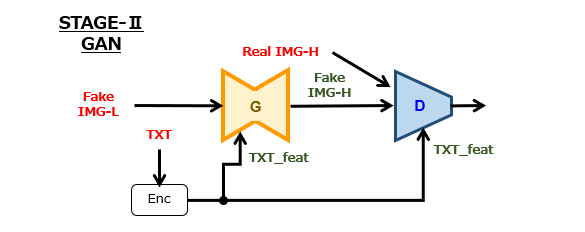
図1と図2を比較すると、Pix2Pix との相違点は、以下の2点と言えるでしょう。
(1)画像サイズの変化
Pix2Pix では、入出力画像のサイズが一致するように生成器が設計されており、変換処理の前後にわたって画像サイズが変化しません。一方、Stage-Ⅱ GAN では、変換処理の前後にわたって画像サイズが変化、つまり拡大します。
(2)テキスト特徴量の入力
Pix2Pix の生成器および弁別器には、画像情報のみが入力されます。一方、Stage-Ⅱ GAN の生成器および弁別器には、画像情報の他に、この画像情報に対応付けられたテキスト特徴量(TXT_feat)が入力されます。
ところが、以下の理由で、Stage-Ⅱ GAN 自体を StackGAN の発明ポイントに認定するのは早計であると思われます。
(1)に関して、低解像度画像から高解像度画像を生成する超解像(Super-Resolution)と呼ばれる技術が前から存在しており、この技術をニューラルネットワークにより実現することに対して特段の困難性がない。
(2)に関して、テキスト特徴量は、画像の生成精度を高める上では有効であるが、必須の入力情報ではない。例えば、[1]生成器に入力/弁別器に非入力、[2]生成器に非入力/弁別器に入力、[3]生成器に非入力/弁別器に非入力、の実装も十分に考えられる。
検討その2(Multi-GANs)
上記した検討によれば、単独のネットワーク構造での差別化は難しいという感触がありました。それでは、StackGAN の本質は何処にあるのでしょうか? 結論ですが、今回の発明ポイントは、複数系列のGANsによる段階的な高解像度化にあると考えます。
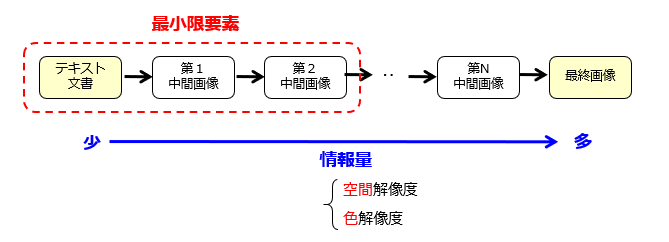
情報量が相対的に少ないデータから多いデータに変換する際、情報量のギャップ(補完すべき情報量)が大きいほど、適正な学習結果が得られない可能性が高くなります。そこで、情報量が異なる中間成果物を準備しておき段階的に学習を行うことで、学習器が挫折することなく高い目標に到達できる、という発想です。
また、図3のように概念的に捉えることで、[1]GANsの系列数は2に限られないこと、[2]画像情報は空間解像度に限られないこと、に気づくことができます。そもそも、[3]入力データがテキスト文書に限られるのか、という疑問も出てきます。
以上、今回(第3回)は、StackGAN の発明ポイントについて考察しました。テーマ最終回(第4回)は、過去3回分の総括として、一連の発明ストーリーを作成します。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。