
Word2Vec(1/4)発明の概要
はぐれ弁理士 PA Tora-O です。今回のテーマとして、自然言語処理(NLP ; Natural Language Processing)の超メジャーなモデルである “Word2Vec" を題材に取り上げていきます。
よくある誤解
色々な技術系ブログなどを読んでいると、Word2Vec に関して、例えば、次のような説明を行っている場合があります。
[文章1]単語のベクトル表現手法は、カウントベースと推論ベースの2種類に大別される。
[文章2]Word2Vec の登場により、推論ベース手法の有用性が示された。
もしAI万能論者がこの2つの文章を繋げると、(A)ニューラルネットワークを初めて導入した “Word2Vec" により、(B)従来型の確率論的手法よりも良い結果が得られるようになった、という意味に曲解しがちです。これは、完全な誤解です。私は、この事例検討を始めるまで、(A)に近いような勘違いをしていました。実は、ニューラルネットワークを用いた推論手法は、“Yoshua Bengio, et al.” によって2003年に既に発表されています。

出展:A Neural Probabilistic Language Model
Word2Vec の特徴
結局のところ、より正確な表現を目指すとなると、概ね以下の通りになると思います。
※ 従来型のカウントベース手法の研究が長年続いているが、近年、ニューラルネットワークを用いた推論ベース手法の研究も盛んになってきた。モデルの簡素化と演算の工夫による処理の高速化を実現した Word2Vec の登場によって、推論ベース手法の高いポテンシャルが示された。
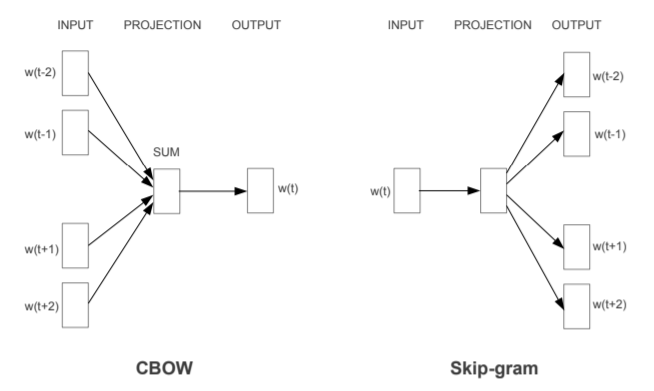
通称 “Word2Vec" は、“Tomas Mikolov, et al.” の一連の論文によって提案された言語処理モデルです。この Word2Vec は、単語から(From Word)ベクトルへ (To
Vector) の変換モデルであり、(1)CBOW、(2)Skip-gram、の2種類のモデルを総称したものです。
(1)CBOW(Continuous Bag-Of-Words)
文脈からターゲットの単語を予測するモデル。
(2)Skip-gram
ターゲットの単語から文脈を予測するモデル。
なお、文脈(コンテキスト/コンテクスト =Context)は、ターゲットの周辺にある1又は複数の単語を意味し、直前の単語、直後の単語、あるいはその両方の単語を含みます。
出展:Efficient Estimation of Word Representations in Vector Space
ここで、図1と図2左側のモデル構造を比較しても違いが分からないと思いますが、図2の方は、中間層(あるいは、投影層)がスリム化されている点に1つの技術的特徴があります。
以上、今回(第1回)は、 Word2Vec の概要について、誤解し易い点を含めて説明しました。この技術を詳しく知りたい方は、インターネットで検索してみてください。次回(第2回)は、CBOWモデルについて詳しく説明します。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。