
全体平均プーリング(2/5)発明の概要
はぐれ弁理士 PA Tora-O です。前回(第1回)では、背景技術としてCNNとプーリングについて説明しました。改めて復習されたい方は、こちらのリンクから確認をお願いします。今回(第2回)は、GAPの概要について説明したいと思います。
問題の所在
図1は、CNNにおける前段演算部(=特徴抽出部)と後段演算部(=情報認識部)の接続状態を模式的に示しています。このように、前段演算部のP層を構成する演算ユニットと、後段演算部のFC層を構成する演算ユニットの間で密に接続されています。通常の場合、2次元マップの位置情報を残しつつ、かつ程良くデータの圧縮が行えるような適切なサイズの演算範囲(つまり、カーネル)が設定されます。
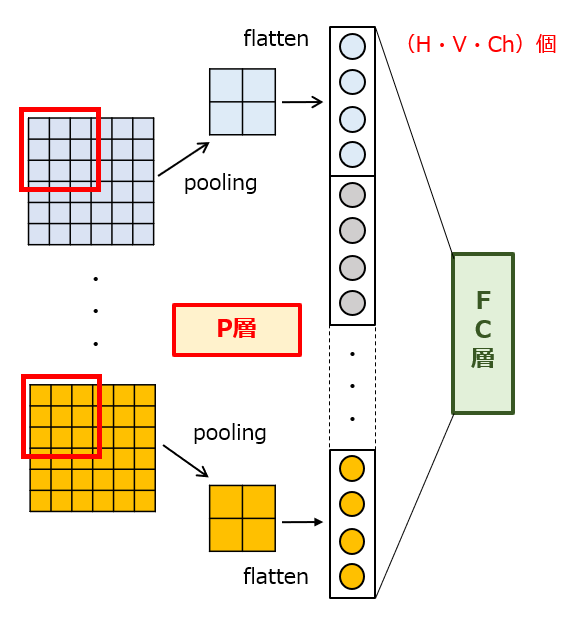
【図1】従来のプーリング演算
例えば、2次元マップのピクセル数がH×V(H,V>1)、チャンネル数がChである特徴マップが得られた場合、後段演算部への入力データ数は、H×V×Chとなります。つまり、特徴マップのボクセルサイズが大きくなるほど結合重みの個数が増えるので、その分だけ後段演算部の学習に要する時間が掛かってしまいます。
解決手段
そこで、上記した問題を解決すべく、GAP(全体平均プーリング)という技術が提案されました。この手法によれば、処理前の2次元マップを構成する全てのピクセル値の平均をチャンネル毎に求めてそれぞれ出力します。図2に示すように、処理後の2次元マップのピクセル値が1個になるので、後段演算部への入力データ数がCh個に削減されます。例えば、処理前のマップサイズが100×100であり、カーネルのサイズが10×10である場合、GAPの実行によって入力データ数が1/(100/10)^2=0.01倍まで削減されることになります。
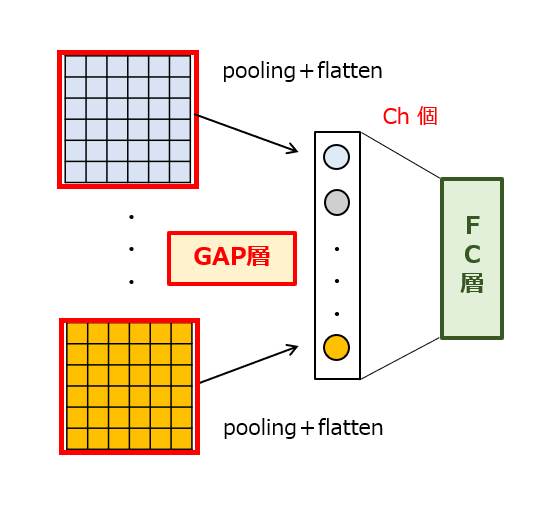
【図2】全体平均プーリング
つまり、GAPとは、処理前のマップサイズに等しいサイズのカーネルを設定した上で、その範囲内で平均プーリングを1回的に行う処理に相当します。このように、GAPを導入することで、従来型のプーリング(非GAP)と同等レベルの認識精度を獲得しつつも、特徴マップのサイズを大幅に削減できる場合があります。
ところで、プーリング処理のカーネルを全体領域(Global Area)に設定する点にGAPの技術的特徴があるため、GAPの「A」は“Area”の頭文字である、とうっかり勘違いしそうです。正しくは“Average”です、覚え間違いに注意しましょう。
実装例
プーリング層(P層)は、Tensorflow/Pythonを用いて、以下のように記述することができます。
tf.nn.avg_pool(input=x,
ksize=[1,2,2,1],
strides=[1,2,2,1],
padding=’VALID’)
ここで、“avg_pool”メソッドの第2,第3引数にある[‥,2,2, ‥]が、カーネルのサイズ/ストライドに相当します。すなわち、このソースコードは、2×2のカーネルを用いた平均プーリングを表現しています。ここで、第2,第3引数を[‥,in_height,in_width, ‥]に書き換えることで、GAPを簡単に実装することができます。なお、(in_height,in_width)は、処理前の2次元マップのサイズに相当します。
以上、今回(第2回)は、GAPの概要について説明しました。次回(第3回)は、GAPの特許性について検討していきます。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。