
Negative Sampling(3/4)作用効果の検討
はぐれ弁理士 PA Tora-O です。前回(第2回)では、“Negative Sampling” の実施例について説明しました。改めて復習されたい方は、こちらのリンクから確認をお願いします。今回は、ドロップアウトとの相違点を念頭に入れながら、“Negative Sampling” に特有の作用効果について深く考察していきます。
ドロップアウト
まずは、比較対象となるドロップアウトの[1]クレーム構成、[2]その構成によって生じる作用・効果、について以下に述べます。なお、今回の検討のため、クレームを一部書き改めています。
【クレーム構成】
3層以上の階層ニューラルネットワークに関して、コンピュータが、以下のステップ(a),(b)を順次繰り返すことを特徴とする学習方法。
(a)1層を構成する複数の演算ユニットの中から一定の割合で1個以上の演算ユニットを無作為に選択し、
(b)選択された演算ユニットの入力、演算または出力を無効化した状態で、ニューラルネットワークに対する学習処理を行う。
【作用と効果】
1層を構成する複数の演算ユニットの中から一定の割合で無作為に選択された演算ユニットの入力、演算または出力を無効化することで、ステップ(a),(b)の実行の度に、元のニューラルネットワークからそれぞれ一定の規模の様々なサブネットワークがランダムに構築される。そして、逐次的に構築されるサブネットワークに対して学習処理を行うことで、疑似的なアンサンブル学習を実現し、アンサンブル学習と同様に、元のニューラルネットワークに対して汎化性能を付与可能となる。これにより、比較的簡単なネットワーク構成でありながら過学習を抑制することができる。
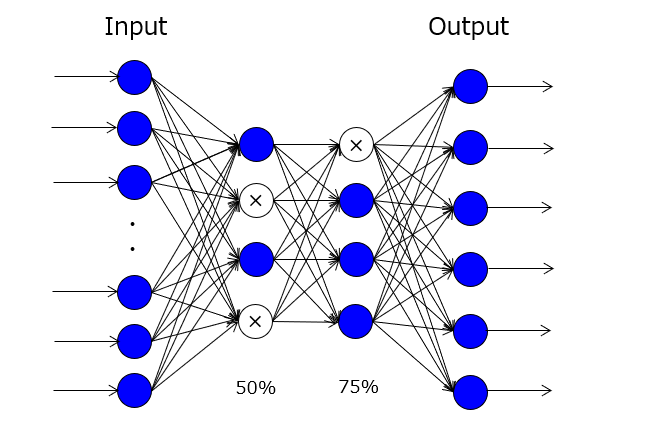
考察
まず、“Negative Sampling” を適用することで、ドロップアウトと同様に、過学習の抑制効果が得られるかどうかが問題になります。答えは「YES」でよいと考えます。これにより、教師データの偏りに伴う分散表現のバラツキが少なくなるという効果は一応得られるでしょう。ところが、このロジックではドロップアウトと大して相違がないことを認めるに等しく、ドロップアウトが公知であることを仮定すれば、“Negative Sampling” の特許性が主張しにくいと言わざるを得ません。
それでは、どのような作用効果を主張するのが好ましいのでしょうか? その突破口は、正例と負例のバランスにあると考えます。
“Negative Sampling” は、「負例の標本抽出」を意味すると思われます。この標本抽出は、母集団の小規模化を通じてデータの取扱性を高めるという目的があります。今回の学習モデルでは、1つの教師データにつき正例が必ず1個含まれることから、この標本抽出により、単語の標本数に占める正例の割合(以下、正例含有率)が相対的に大きくなります。つまり、正例/負例のアンバランスを是正することで学習効率が高くなり、その結果、学習の終了までに要する時間の短縮化が図られます。
具体例で説明すると、授業のシーンで、先生が正解のみを教えるのでは生徒の応用能力が身に付かず、その一方で先生の雑談が多すぎると生徒の学習効率が落ちる、ということでしょうか。
まとめ
“Negative Sampling” による効果を図2にまとめました。ネットワーク構造上の見た目に囚われて「ユニット使用率」の変更に着目しただけでは、ドロップアウトとの差別化が困難になります。これに対して、教師データの正例/負例の違いを考慮して「正例含有率」に着目することで、ドロップアウトとの差別化が図れるようになりました。
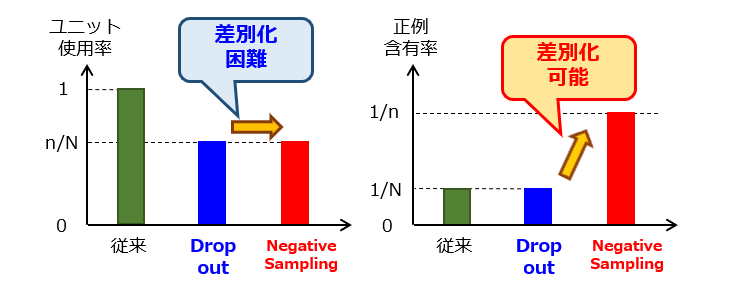
以上、今回(第3回)は、“Negative Sampling” の作用効果について説明しました。テーマ最終回(第4回)は、これまでの検討の総括として発明ストーリーを完成させます。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。