
Pix2Pix(2/4)実施例の説明
はぐれ弁理士 PA Tora-O です。前回(第1回)では、Pix2Pix の概要について説明しました。改めて復習されたい方は、こちらのリンクから確認をお願いします。今回(第2回)は、Pix2Pix の実施例について説明します。
CGANベースの Image-to-Image モデル
早速ですが、前回出した検討課題の解答例を図1に示します。図1の例では、CGANの基本モデルに「X:エッジ抽出処理」と「Y:符号化処理」を追加してみました。
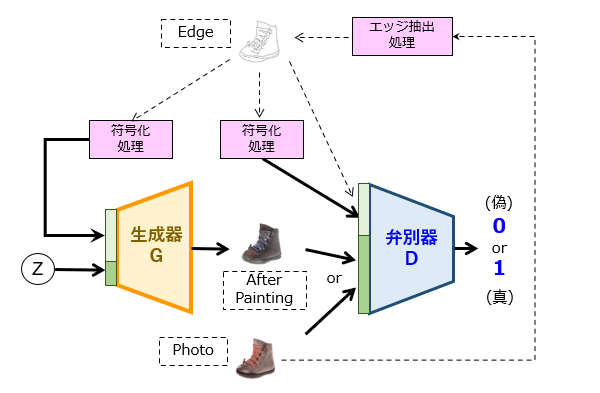
1番目のエッジ抽出処理は、「生成後の模範画像」としての写真から、「生成前の画像」としての線画を作成するための処理です。ここでは、生成器に「塗り絵」をさせる場合を想定していますが、写真に対して、[1]色情報の削減、[2]空間情報の削減、[3]画像情報の変換、などを行うための様々な加工処理が適用され得る、ということです。
2番目の符号化処理は、「条件」としての情報の入力量を削減するための処理です。典型的には、畳み込みニューラルネットワーク(CNN)が使えそうです。2つの符号化処理は、いずれも同一の演算を行います。ただし、弁別器側の符号化処理は必須ではなく、弁別器に線画を直接入力しても構いません。この場合、例えば、写真又は塗り絵が有する「RGBチャンネル」に線画の「Kチャンネル」を連結(Concatenate)した4チャンネルの画像として取り扱うことが想定されます。
Pix2Pix のネットワーク構造
上記したモデルでも所望の変換処理を十分に実現できそうですが、実際の Pix2Pix モデルはこれとは少々異なり、図2に示す通りになります。
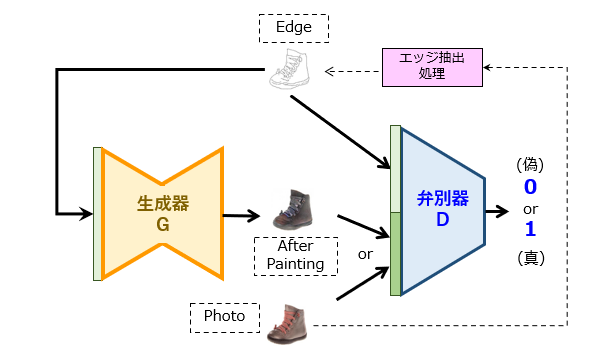
図1と図2を見比べると明らかですが、Pix2Pix の特徴の1つとして、生成器および弁別器の中に、線画の符号化機能がそれぞれ取り込まれている点にあります。つまり、生成器は、「線画」画像を入力とし、「塗り絵」画像を出力とするニューラルネットワークになります。本論文には、生成器の具体的な構成が例示されています(図3)。
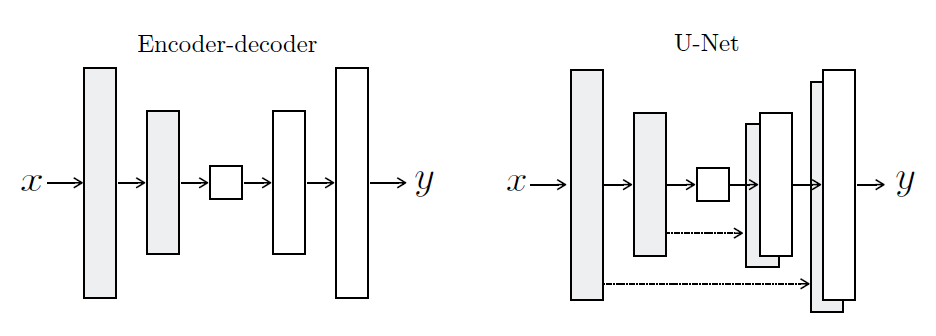
出展:Image-to-Image Translation with Conditional Adversarial Networks
左右のモデルに共通するのは、エンコーダとしてのCNNと、デコーダとしてのDNNが直列的に接続されている点です。ところが、左側の “Encoder-Decoder” ではCNNの最下流側とDNNの最上流側のみが接続されるのに対して、右側のU-Netでは、CNNとDNNの対応する層同士がそれぞれ接続されています。この接続を “Skip Connection” と呼びます。今回の検討では説明を省略しますが、U-Netに関してもいずれ事例検討を行ってみたいと思います。
以上、今回(第2回)は、Pix2Pix の実施例について説明しました。次回(第3回)は、図1と図2の対比の中であえて触れなかった部分について概念的に解説してみます。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。