
R-CNN(1/2)発明の概要
はぐれ弁理士 PA Tora-O です。今回のテーマとして、物体検出手法の基本とも言えるR-CNNを題材に取り上げていきます。ちなみに、このCNNは、畳み込みニューラルネットワーク(Convolutional Neural Network)の略記です。
タスクの定義
最初に、画像認識時に実行されるタスクの定義について簡単に説明します。以下に述べるように、物体検出は、画像分類と比べてかなり高難度なタスクであると言えます。
画像分類(Image Classification)は、1枚の画像に対して1つの分類結果を求めるタスクです。この場合、認識対象の画像ごとにラベルが付与されています(図1)。

物体検出(Object Detection)は、1枚の画像に含まれる1以上の物体の検出結果を求めるタスクです。1枚の画像に複数の物体が写り込む場合もあり得るため、このタスクでは、物体の位置および種類の両方を同時に検出する必要があります(図2)。

R-CNNの概要
従来の画像認識には、SIFT(Scale-Invariant Feature Transform)やHOG(Histogram Of Gradient)などの特徴量に基づく手法が用いられてきました。2012年にCNN型の画像分類器である“AlexNet”が登場すると、より高度なタスクである物体検出に対してもCNNを導入する技術トレンドが発生しました。以下、R-CNN(Regions with CNN features)の論文を紹介します。
Rich feature hierarchies for accurate object detection
and semantic segmentation
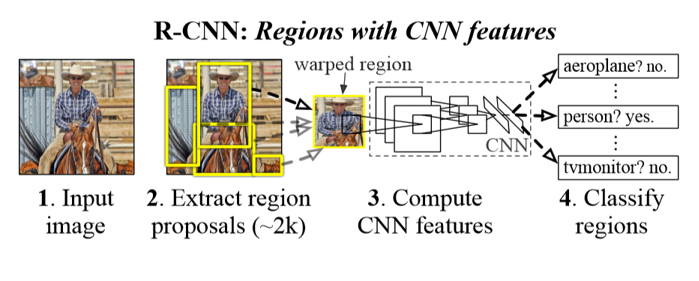
1.Input image
検出対象の画像を入力します。画像のサイズに制限はありません。
2.Extract region proposals
既存の手法(ここでは、Selective Search)を用いて、入力画像の中から複数の領域候補(region proposals)を抽出します。得られた領域候補のそれぞれをCNNの入力サイズに合わせて変形・リサイズします。この処理は、ワーピング(warping)とも呼ばれます。
3.Compute CNN features
特徴抽出器として機能するCNNを用いて、領域候補ごとの特徴マップを出力します。CNNの構成例として”AlexNet”や”VGG”が用いられます。
4.Classify regions
CNNで抽出した特徴マップを用いて、サポートベクターマシン(SVM)により物体の有無および種類を分類します。該当/非該当の2値を出力するSVMの場合、物体の種類ごとに学習器を準備する必要があります。同様に、CNNで抽出した特徴マップを用いて、回帰演算(Regression)により物体の境界ボックス(Bounding Box)の位置を推定します。
以上、今回(第1回)は、R-CNNの概要を説明しました。次回(第2回)は、クレーム骨子を作成してみます。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。