
アテンション機構(1/4)発明の概要
はぐれ弁理士 PA Tora-O です。今回のテーマとして、ニューラル機械翻訳(NMT)における頻出の手法であるアテンション機構(Attention Mechanism)を題材に取り上げていきます。
背景
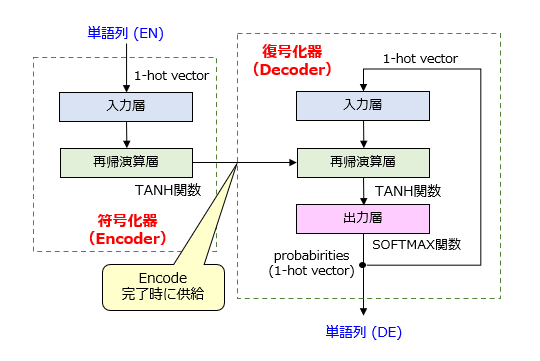
いわゆる “Word2Vec” の登場を皮切りに、自然言語処理(NLP)の研究分野においてニューラルネットワークを用いる動きが活発になってきました。例えば、自動翻訳(あるいは、機械翻訳)の分野において、エンコーダ部分とデコーダ部分に相当する2種類の再帰型ニューラルネットワーク(RNN)を接続して構成されるEncoder-Decoderモデル(いわゆる、Seq2Seq モデル)が提案されました。図1は、Seq2Seq のネットワーク構造の一例を示しています。
アテンション機構の導入
そして、この Seq2Seq モデル(Sutskever et al.)の発表から約1年後、アテンション機構を組み込んだ新しいモデル(Luong et al.)が発表されました。アテンション機構自体は、画像認識における手法として既に知られていた技術ですが、NLPに適用されたのは本論文がおそらく初めてだったようです。
(参考:Recurrent models of visual attention)
以下の図2は、アテンション機構の概略図を示しています。青いブロックがエンコーダ部分、赤いブロックがデコーダ部分に相当します。
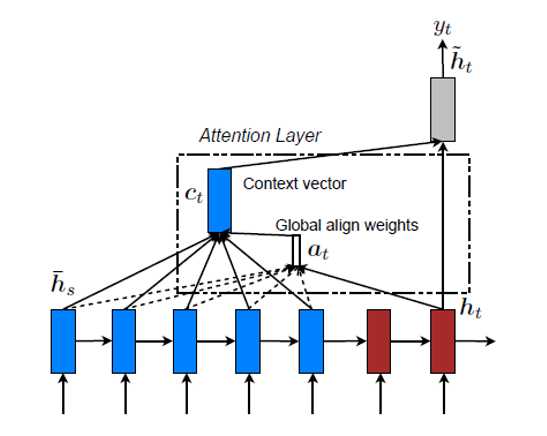
出展:Effective Approaches to Attention-based Neural Machine Translation
次回以降でパラメータ定義や演算方法の詳細を説明しますが、この図における Global align weights{a(t)}が「注意度(Attention)」であると読み替えた方が理解しやすいでしょう。
効果
上記したモデル(Seq2Seq with Attention)により、既存のモデル(without Attention)と比べて翻訳精度が向上したと報告されています。そして何よりも、ブラックボックスであったニューラルネット君の処理過程の一部を、人間に対して説明可能(accountable)な状態で出力できるという利点があります。

出展:Effective Approaches to Attention-based Neural Machine Translation
この図3では、独語→英語の翻訳時における英単語と独単語の対応関係がマップ化されています。マップの色は、黒いほど注意度が低く、白いほど注意度が高いことを可視的に示しています。このマップを用いれば、例えば、独単語の ”Sie” は、英単語の “They” や “understand” との間で関係性が高いことを一目で把握することができます。
以上、今回(第1回)は、アテンション機構について、その背景を含めて説明しました。次回(第2回)は、アテンション機構の実施例について説明します。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。