
GAN(3/4)GANの特徴
はぐれ弁理士 PA Tora-O です。前回(第2回)では、GANの実施例について説明しました。改めて復習されたい方は、こちらのリンクから確認をお願いします。今回(第3回)は、VAEと比較した場合のGANの強みについて解説します。
VAEとGAN
まず、比較対象であるVAE(Variational Autoencoder)の特徴について軽く触れます。必要であれば、以下のリンクから復習してください。
事例 #015 VAE
VAEは、学習データセットを潜在的空間(Latent Space)上の特徴ベクトル{z}として埋め込み、AEの学習完了後にエンコーダ部分を切り離すことで、特徴ベクトル{z}から様々なデータを生成する生成器(デコーダ部分)を構築する手法です。
VAEでは、通常のAEとは異なり、学習データセットを構成する個々の学習データのみならず、その学習データ同士の中間状態を確率論的に表現することで、複数の学習データを尤もらしくアレンジして新たなデータを創作する能力をデコーダに学習させます。つまり、VAEは、学習データの再現精度よりも、生成データの中間表現力に重点を置いた手法であると言えます。
これに対して、前回(第2回)に説明した元祖GAN(Vanilla GAN)は、学習データセットを潜在的空間上の特徴ベクトル{z}として埋め込む点では共通しますが、学習データセットを構成する個々の学習データが何処の小領域に属するか、という領域区画問題を解いています。つまり、学習データ同士の中間状態を排他的に表現することで、学習データの完コピ(Exact Copy)を目指しています。このように、元祖GANは、生成データの中間表現力は一切無視して、学習データの再現精度に特化した手法であると言えます。
以上の考察から、元祖GANは、生成モデルというよりも、学習データと同一物を人工的に生成する再現モデルと分類されるべきでしょう。
GANの拡張性
それでは、GANは、新しいデータを人工的に生み出すという意味での「生成モデル」として不向きなのでしょうか? 答えは、NOです。その理由について、CGAN(Conditional GAN)の例を挙げて説明しましょう。以下、CGANの構成の一例を図1に示します。
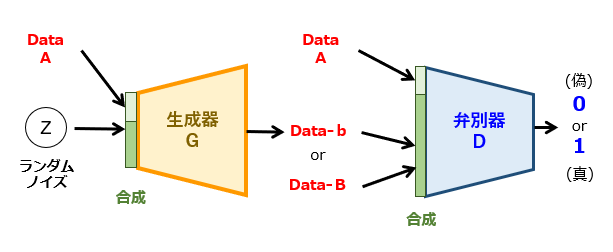
CGANのネットワーク構成は、元祖GANの場合と基本的には同じです。ところが、生成器および弁別器に入力されるデータが異なります。具体的には、CGANでは、元祖GANにおける入力データ(G:ノイズ/D:データb)に対して、これとは全く別のデータ(ここでは、データA)がそれぞれ追加されています。つまり、生成器の機能のみに注目すると、両者の違いは次のように表現できます。
元祖GAN:無から「データb(≒B)」を生成
CGAN :「データA」から「データb(≒B)」に変換
ここで、データA,Bは、任意の形式であり、互いに同種であってもよいし、異種であっても構いません。一例として、CGANを用いたデータ変換結果を図2に示します。

出展:Conditional Generative Adversarial Nets(一部加工あり)
我々の理解としては、CGANが「データA=任意」である一般モデルであり、元祖GANが「データA=NONE」である特殊モデルと捉えればよいでしょう。そのように考えると、{z}をノイズと表現することに納得できますね。
GANの本質
このように、CGANまで発展すれば、GANはとても拡張性・応用性が高いモデルであると想像できるでしょう。その理由が、GANという発明の本質に繋がると思われます。それでは、何故でしょうか? 答えは、意外とシンプルです。
GANの弁別器が、入力データの真贋判定しか行わない、生成器とは独立したニューラルネットワークだから。(50文字)
テーマ最終回(第4回)では、この発言の真意を明確にすべく一連の発明ストーリーを作成しつつ、全体を総括します。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。