
アテンション機構(2/4)全体構成の説明
はぐれ弁理士 PA Tora-O です。前回(第1回)では、アテンション機構の概要について説明しました。改めて復習されたい方は、こちらのリンクから確認をお願いします。今回(第2回)は、アテンション機構の実装例として、“Seq2Seq with Attention” の全体構成について説明します。
エンコーダの構造
まず、エンコーダのネットワーク構造を図1に示します。
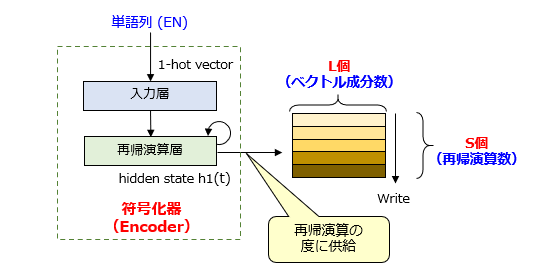
エンコーダは、入力層と、1層以上の再帰演算層から構成されます。再帰演算層は、単純RNN、LSTM、GRUのいずれであっても構いません。エンコーダの構造は、「アテンション無し」と全く同じです。が、唯一の違いは、出力される特徴量のデータ構造にあります。「アテンション無し」の特徴量は、最終的に生成される1つの隠れ状態ベクトルのみです。これに対して、「アテンション有り」 の特徴量は、逐次的に生成される複数の隠れ状態ベクトルの集合体です。
具体的には、エンコーダは、再帰演算を実行する度に、計算したL次元の隠れ状態ベクトルh1(t) を出力します。この結果、S回の再帰演算を通じて、h1(t) の時系列集合を示す(S×L)の隠れ状態行列が得られます。簡単に言えば、取り扱う情報量がS倍に増えたという程度でしょうか。
デコーダの構造
続いて、デコーダのネットワーク構造を図2、図3に示します。
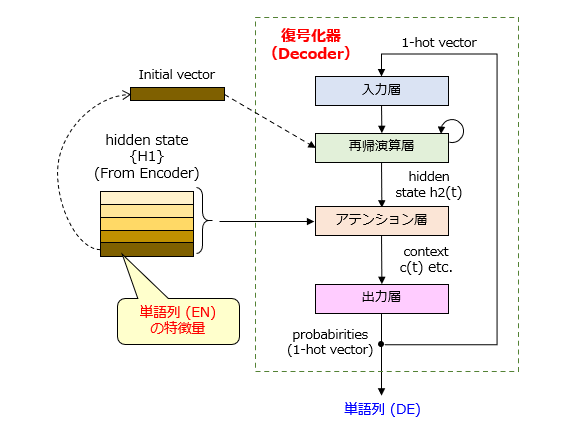
図2に示すように、デコーダは、入力層と、再帰演算層と、アテンション層と、出力層から構成されます。「アテンション無し」との大きな相違点は、再帰演算層と出力層の間に「アテンション層(機構)」が設けられていることです。アテンション層は、隠れ状態行列{H1}と隠れ状態ベクトルh2(t) を用いて、コンテキストベクトルc(t) を計算します。
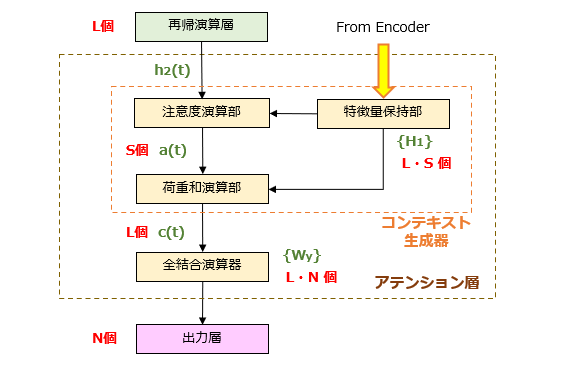
図3に示すように、アテンション層は、コンテキスト生成器と、全結合演算器から構成されます。ここで、コンテキスト生成器のサブ構成について簡単に説明します。
(1)特徴量保持部
エンコーダにより生成された隠れ状態行列{H1}を保持します。ちなみに、「アテンション無し」では、隠れ状態ベクトルh1は、再帰演算層に投入された後、値を変えながら逐次的に更新されます。このように、符号化された特徴量をそのまま保持するという概念は、新しい特徴であると言えるでしょう。
(2)注意度演算部
S個の隠れ状態ベクトルh1に対する注意度a(t) を計算します。注意度a(t) は、隠れ状態ベクトルh1、h2(t) 同士の類似スコアを示すパラメータであり、S個の総和が1になるように[0,1]の範囲で正規化された値です。例えば、h2(t) が2番目のベクトル(つまり、隠れ状態行列の第2行)に一致する場合、注意度は、a(t) =(0,1,0,・・・,0)、あるいは、このベクトルに近い値になります。
(3)積和演算部
S個の隠れ状態ベクトルh1に対して注意度a(t) を重み付けした積和演算を実行します。つまり、コンテキストベクトルc(t) とは、隠れ状態行列{H1}をソースとして計算される中間的な特徴量とも言えそうです。
以上、今回(第2回)は、“Seq2Seq with Attention” の全体構成について説明しました。次回(第3回)は、アテンション機構の変形例について検討します。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。