
CycleGAN(3/4)学習のメカニズム
はぐれ弁理士 PA Tora-O です。前回(第2回)では、CycleGAN の実施例について説明しました。改めて復習されたい方は、こちらのリンクから確認をお願いします。今回(第3回)は、CycleGAN における学習のメカニズムについて独自の解釈で説明を試みます。
Identity Loss
と、その前に、目的関数(Objectives)の第3要素であるアイデンティティ損失(Identity Loss)について触れておきます。この損失項はオプションですが、学習のメカニズムとの関連性が深いため、図1を用いて簡単に説明します。
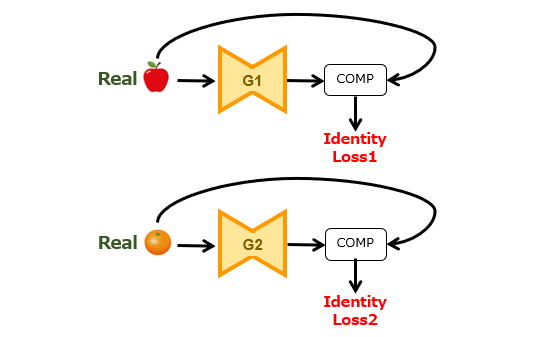
アイデンティティ損失は、具体的には、
[1]リンゴ画像を生成器G1に投入すると、そのままの画像が出力されること。
[2]オレンジ画像を生成器G2に投入すると、そのままの画像が出力されること。
の2つの制約を課しています。つまり、この損失項は、画像群に共通するアイデンティティ(自己同一性)の不変性/普遍性を担保するための仕組みといえます。
このアイデンティティは、画像の全体領域に存在する場合(例えば、絵画の色使いやタッチ)もあれば、画像の部分領域のみに存在する場合(例えば、本例のようなリンゴ/オレンジの有無)もあり得ます。よって、様々な形態のアイデンティティをカバーできるように、画像の全体領域を対象として、各画像の一致性を評価するのが良さそうです。
学習メカニズムの概説
前置きが長くなりましたが、CycleGAN の学習メカニズムについて、独自に図解してみました。図2は、リンゴ画像の生成器G1の学習プロセスを模式的に示しています。オレンジ画像の生成器G2についても、これと同様です。
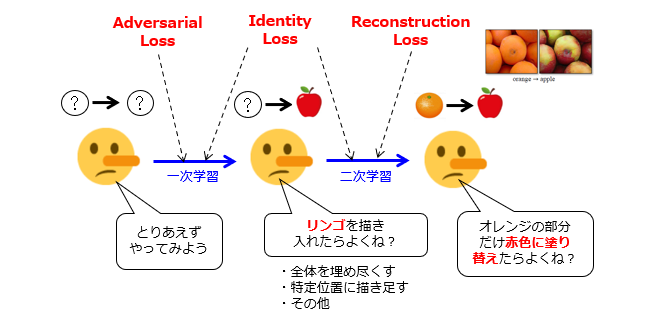
A.2つの学習ステップ
説明の便宜上、一連の学習プロセスを2つのステップに分解しました。実際の学習では、この2つのステップが同時に進行するものと考えてください。
左側の生成器G1は、学習前の状態を示しています。ここで、生成器G1は、タスクの目的を理解していないので、どのような画像が入力され、どのような画像を出力すればよいのかを知りません。
中央の生成器G1は、一次学習が進んでちょっと賢くなった状態を示しています。ここで、生成器G1は、リンゴを含む画像を出力すれば高評価が得られる、という知識を獲得しています。リンゴの描き入れ方は、[1]画像全体を埋め尽くす、[2]画像領域内の特定位置に描き足す、などの様々な手法が考えられますが、どの手法を採用すべきかを特に意識していません。
右側の生成器G1は、二次学習が進んでさらに賢くなった状態を示しています。ここで、生成器G1は、(a)入力される画像に必ずオレンジが含まれる、(b)元の画像からの変更量を必要最小限に留めてリンゴ画像を出力すれば高評価が得られる、という知識を獲得しています。その結果、生成器G1は、オレンジ部分の色を塗り替えてリンゴを偽造する、という悪知恵(?)を働かせるようになります。
B.各損失との対応関係
敵対的損失(Adversarial Loss)は、生成器G1が弁別器D1を欺くように作用するので、「一次学習」に寄与すると言えます。再構成損失(Reconstruction Loss)は、画像変換の可逆性が獲得できるように作用するので、「二次学習」に寄与すると言えます。
これに対して、アイデンティティ損失(Identity Loss)は、画像群のアイデンティ(リンゴ/オレンジ)を認識・維持するように作用します。つまり、前者(=認識)の機能は「一次学習」に、後者(=維持)の機能は「二次学習」にそれぞれ寄与すると言えるでしょう。ただし、この損失項のみで一次学習および二次学習の両方を実現できる訳ではなく、学習を促進する補助的な役割を果たすに過ぎません。
このように解釈することで、敵対的損失および再構成損失は目的関数のMUST要素であり、アイデンティティ損失は目的関数のWANT要素であることが上手く説明できました。
以上、今回(第3回)は、CycleGAN の学習メカニズムについて解説しました。テーマ最終回(第4回)は、過去3回分の総括として、一連の発明ストーリーを作成します。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。