
GAN(2/4)実施例の説明
はぐれ弁理士 PA Tora-O です。前回(第1回)では、GANの概要について説明しました。改めて復習されたい方は、こちらのリンクから確認をお願いします。今回(第2回)は、GANの実施例について、生成器の学習方法を中心に説明します。
全体の流れ
改めて説明する必要がないほど有名な話ですが、GANは、紙幣の偽造モデルによく例えられます。偽造者(=Generator)は本物に近い偽札を作ろうとし、警官(=Discriminator)はそれが偽物であると見抜こうとします。偽造者は、より精巧な偽札を作り出すように技術を磨くことで、最終的には本物に近い偽札を作ってしまう、という道徳上良くない話です。
GANでは、[1]学習用画像の準備、[2]弁別器の学習、[3]生成器の学習、の3つのフェーズを繰り返すことで、上記のいたちごっこを模した学習が行われます。それでは、具体的な実現方法について説明しましょう。
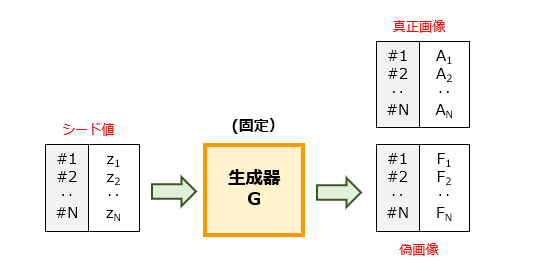
第1フェーズ:学習用画像の準備
第1フェーズでは、まず、再現を試みるN個の真正画像(Authentic Images)を準備します。そして、画像の生成源であるN個のシード値{z}を無作為に生成します。このシード値{z}は、潜在的空間(Latent Space)上のL次元ベクトルに相当します。そして、シード値{z}を生成器に順次投入することで、N個の偽画像(Fake Images)を生成します。
このようにして、合計2N個の学習用画像が準備できました。以降、N組のシード値{z}は、当該フェーズの実行の度に改めて生成されます。したがって、N組というのは正例/負例のバランスを1:1に保っているにすぎず、個々の真正画像に対応する偽画像を作成している訳ではない点に注意です(M組でも構いません)。
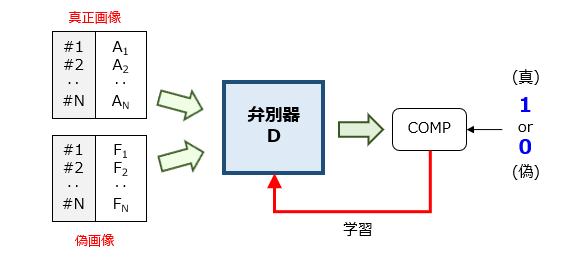
第2フェーズ:弁別器の学習
第2フェーズでは、先に準備された2N個の画像を用いて、弁別器に「教師あり学習」を施します。この学習では、入力された画像がN個の真正画像のうちの1つである場合に「1」を、N個の偽画像のうちの1つである場合に「0」をそれぞれ教示します。その結果、弁別器は、生成器が目下に生成した画像が偽物であることを見破る弁別能力を獲得しました。
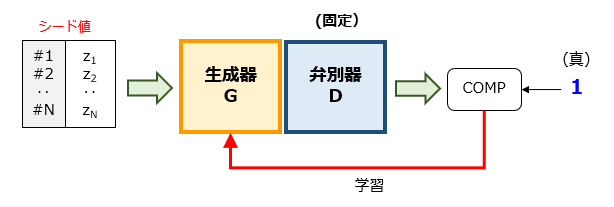
第3フェーズ:生成器の学習
第3フェーズでは、先に生成されたN組のシード値を用いて、生成器に「教師あり学習」を施します。この学習では、生成器と弁別器が直列的に接続された状態で、入力されたN組のシード値{z}のいずれに対しても「1」を教示します。その結果、生成器は、弁別器が目下に弁別した判断を誤らせる画像の生成能力を獲得しました。
以上のようにして、第1~第3フェーズを繰り返すことで、敵対的(Adversarial)な関係にある生成器および弁別器が、相互学習を通じて強化されています。
以下、蛇足の説明です。上述した偽札(人間対人間)の話であれば、真贋を弁別するチェックポイントが形式知化された場合、次回以降でこのチェック項目を追加すれば足りるため、第2フェーズにおける真正画像の再学習は不要と思われます。ところが、AI(ニューラルネット)ではこのような弁別ルールがブラックボックス化されるので、画像の弁別精度を担保する観点から、真正画像の再学習がその都度必要になる点に留意しましょう。
以上、今回(第2回)は、GANの実施例について説明しました。次回(第3回)は、VAEと比較した場合のGANの強み(Strong Point)について説明します。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。