
GAN(1/4)発明の概要
はぐれ弁理士 PA Tora-O です。今回のテーマとして、深層生成モデルの基礎とも言うべきGAN(Generative Adversarial Network)を題材に取り上げていきます。
背景
生成モデル(Generative Model)とは、所与の学習データセットをベースに、学習データとは異なる新しいデータを人工的に生成するためのモデルです。データの種類は、静止画、動画、音楽、音声、文章(小説、俳句、チャットなど)など多岐にわたりますが、以下、画像(静止画)を例に挙げて説明していきます。画像は、多値(8ビットの場合は、256通り)の中から選択し得る画素値を有する多数の画素(例えば、100×100画素)からなるデータであり、場合によっては複数のカラーチャンネル(RGB)をもっています。つまり、画像領域の全体的または局所的なバランスを考慮しつつ、より自然な状態で違和感なく仕上げる必要があることから、「画像生成」はかなり難度が高いタスクであると言えます。
従来では、マルコフ連鎖モンテカルロ法(MCMC法)などを含む統計的手法が主流でしたが、画像を完成させるまでの演算時間が掛かるという問題がありました。そこで、学習フェーズには演算時間が掛かるものの、生成フェーズには演算時間がそれほど掛からないニューラルネットワークを用いた新しい手法が出現しました。ニューラルネットワーク系の生成モデルは、
[1]VAE(Variational Autoencoder)
[2]GAN(Generative Adversarial Network)
の2種類に大別されます。前回にVAEの事例検討を無事に終えたので、今回は、後者のGANについて事例検討を進めます。
発明の概要
GANは、VAEの発表から少し後に(と言っても同じ2014年ですが)、イアン・グッドフェロー氏(Ian Goodfellow)によって提案されました。このGANは、AI研究の先駆者の一人であるヤン・ルカン氏(Yann LeCun)に、 “the most interesting idea in the last 10 years in ML" と言わしめたほどの斬新なアイディアです。それでは早速、GANの概要について図示してみましょう。
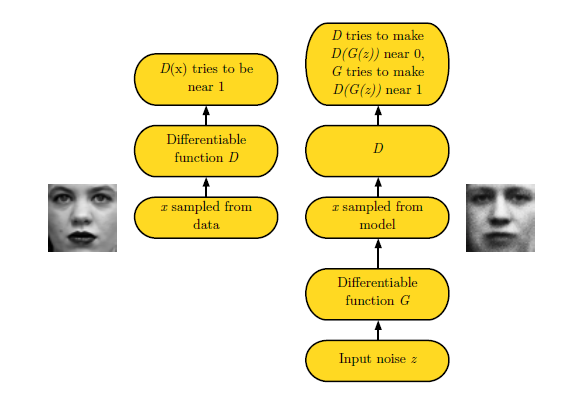
出展:NIPS 2016 Tutorial: Generative Adversarial Networks
この図面だけではちょっと何言ってるかわからないので、軽く説明します。
図の「G」は生成器(Generator)を、「D」は弁別器(Discriminator)をそれぞれ表しています。また、図の左側は「真正」の画像に対する処理流れを、右側が「偽(にせ)」の画像に対する処理流れをそれぞれ示しています。生成器Gおよび弁別器Dの行動原理は、概ね以下の通りです。
・生成器Gは、シード値(z)から画像を生成する。
・弁別器Dは、真正の画像に対して正解(1)、真正でない画像に対して不正解(0)であるとそれぞれ回答する。
・生成器Gは、弁別器Dに、自身が生成した画像が正解(1)であると回答させようと頑張ってみる。
・弁別器Dは、生成器Gが生成した画像が不正解(0)であると回答しようと頑張ってみる。
上記した内容がまさに発明のポイントと思われますが、このままではGANの事例検討が今回限りで終わってしまいます。ここで諦めたら試合終了なので、もう少し具体的な検討を進めてみます。結果的に何も得られない可能性もありますが。
以上、今回(第1回)は、GANの概要について説明しました。次回(第2回)は、GANの実施例について説明します。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。