
Negative Sampling(1/4)発明の概要
はぐれ弁理士 PA Tora-O です。今回のテーマとして、自然言語処理で多用される技術の1つである “Negative Sampling” を題材に取り上げていきます。
この手法は、“Tomas Mikolov, et al” による論文(いわゆるWord2Vec)で提案されており、CBOW/Skip-gramモデルに対する学習処理の高速化を図ることを目的としています。以下の事例検討では、上記した2種類のモデルに関する知識があることを前提に話を進めるため、まずはこちらの記事(Word2Vec)を先に読むことをお勧めします。
背景
単語の分散表現を獲得する手法として、連続する単語の配列パターンを学習し、結合重み行列からベクトルを求める手法が挙げられます。例えば、図1のように、CBOW(Continuous Bag-Of-Words)モデルの学習を通じて最適化された線形変換行列により、N次元のワンホット表現をL次元の分散表現に変換します。
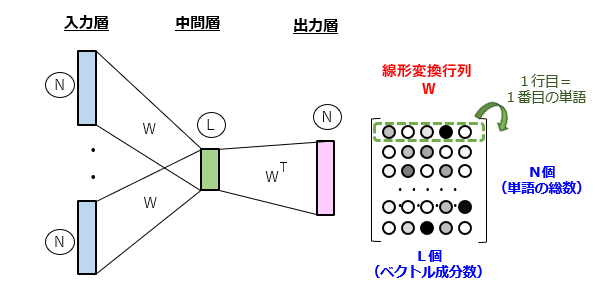
問題の所在
“Word2Vec” の記事で既に説明した通り、「文章の穴埋め問題」というタスクを与えることで、ニューラルネット君に単語の配列パターンを学習させます。このタスクの実行中に、入力層→中間層→出力層へのフォワード処理に伴い、(N×L)又は(L×N)行列 の重み付け和を求める荷重和演算を行う必要があります。「入力層→中間層」の前段処理に関して言えば、入力側が “one-hot vector”であるという特殊性から、上記した「ベクトル抜き出し法」によって荷重和演算を省略することができます。ところが、後段処理の「中間層→出力層」についてはそう上手くいきません。
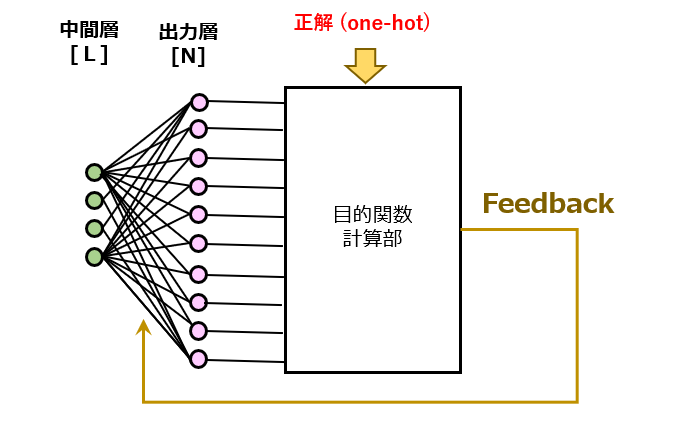
例えば、N=10000、L=100の荷重和演算では、合計(N×L+L)=1,000,100回、つまり、約百万回もの四則演算を行う必要が生じます。たった1組の学習パターンだけでもこの回数ですから、学習処理が終了するまで相当な時間を要することが容易に想像できます。
解決手段
そこで、上記した問題を解決すべく、“Negative Sampling” という手法が提案されました。まずは、図2と見比べる体で、図3を参照してください。この図3を見て、とある別の技術が頭に浮かんだ方は、もはやAIの達人です。
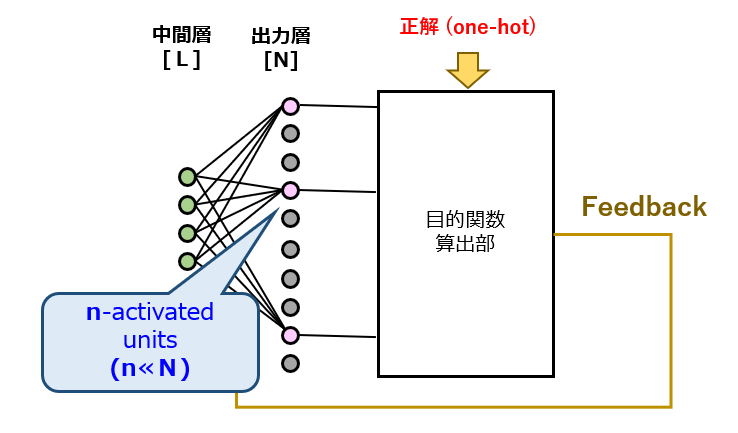
正解は、過去にも事例検討を行ったことがある「ドロップアウト」です。確かに、ドロップアウトと似ている部分がありますが、ちょっと変則的になっています。演算ユニットの無効化規則がどのように変わっているのか、“Negative Sampling” の呼び名がヒントになっています。
以上、今回(第1回)は、“Negative Sampling” について、その背景を含めて説明しました。次回(第2回)は、“Negative Sampling” の実施例について検討していきます。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。