
Selective Search(2/4)発明の概要Ⅱ
はぐれ弁理士 PA Tora-O です。今回(第2回)も引き続き、”Selective Search” の実施例について詳しく説明します。なお、前回(第1回)の復習を行う際は、こちらのリンクからお願いします。
前回は、フローチャートのステップS1まで説明しました。公知の領域分割手法を用いて、複数の初期領域を取得したところです。
S2:色特徴量の計算
次に、ステップS2では、ステップS1で得られた領域毎の色特徴量を計算します。この色特徴量は、デバイス依存色空間(Device Dependent Color Space)上、またはデバイス非依存色空間(Device Independent Color Space)上で定義される色値です。前者の代表例はCIERGB、後者の代表例はCIELABで、いずれもカラーマネージメントシステム(CMS)でよく使われるものです。
具体的には、(1)RGB、(2)グレースケール画像のI、(3)Lab、(4)[0,1]で正規化済みのRGI、(5)HSV、(6)[0、1]で正規化済みのRGB、(7)C、(8)H、が用いられるそうです。
S3:類似度の計算
次に、ステップS3では、ステップS2で求めた色特徴量を用いて、隣接する初期領域同士の類似度(Similarity)を計算します。ここでは、以下に示す4種類の個別類似度の重み付け和を 類似度 S(ri,rj) と定義しています。つまり、カラー・テクスチャ・サイズ・包含関係の様々な観点から総合的な類似度を求めることがポイントです。
[1]カラー類似度 Scolour(ri,rj)
[2]テクスチャ類似度 Stexture(ri,rj)
[3]サイズ類似度 Ssize(ri,rj)
[4]包含関係類似度 Sfill(ri,rj)
これらの個別類似度は、[0,1] の範囲内の値をとり、1に近いほど類似度が高く、0に近いほど類似度が低くなるように定義されています。いずれも、”Selective Search” 論文中に具体的な計算式が記載されています。
S4:階層的グループ化
次に、ステップS4では、ステップS3で求めた類似度を用いて、階層的グループ化(Hierarchical Grouping)を行います。図1の赤字枠で囲んだ部分です。

出展:Selective Search for Object Recognition
ざっくり言えば、初期領域がすべて併合されて1個の領域のみになるまで、次の3つのサブステップを順次繰り返して実行します。
[S4a]類似度が最大となる隣接領域ペア(rp,rq)の選択
[S4b]該当する隣接領域ペア(rp,rq)の併合 ⇒ rt
[S4c]併合後の類似度 S(ri,rt) を再計算
図2は、グループ化の過程を模式的に示しています。ここでは、3枚の領域マップしか表記していませんが、実際には、その間に多くの領域マップが存在しています。
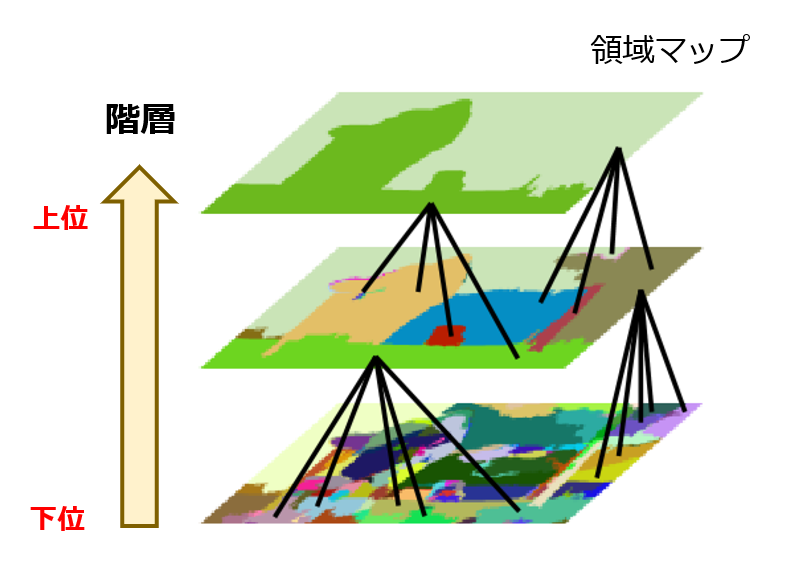
出展:Selective Search for Object Recognition(一部加筆)
最後までもう一息ですが、今回(第2回)はこれで終了とします。次回(第3回)は最後のステップS5(境界ボックスの設定)を説明した後、”Selective Search” の発明ポイントを特定します。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。