
Doc2Vec(1/5)発明の概要
はぐれ弁理士 PA Tora-O です。今回のテーマとして、Word2Vec の発展的モデルである “Doc2Vec”を題材に取り上げていきます。
背景
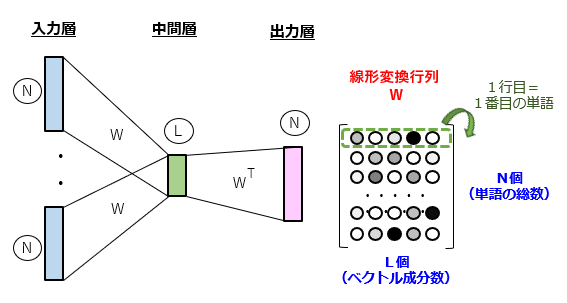
近年、自然言語処理(NLP)の研究分野において、従来型のカウントベース手法とは異なる、ニューラルネットワークを用いた推論ベース手法の研究も盛んになっています。特に、モデルの簡素化と演算の工夫による処理の高速化を実現した Word2Vec の登場によって、推論ベース手法の高いポテンシャルが示されました。“Word2Vec” によれば、単語の分散表現(連続値成分のベクトル化)を行うことで、単語間の関係性を定量的に表現することを目指しています。具体的には、図1のように、CBOW(Continuous Bag-Of-Words)モデルの学習を通じて最適化された線形変換行列により、N次元のワンホット表現をL次元の分散表現に変換します。
ところで、複数の単語(Word)を組み合わせることで文章(Sentence)が、複数の文章を組み合わせることで段落(Paragraph)が、複数の段落を組み合わせることで文書(Document)が構成されます。つまり、Word2Vec のような手法を用いることで、単語だけではなく、文章・段落・文書の分散表現も可能ではないか、と考えられます。
概要
そこで、“Word2Vec” をベースとした手法である “Doc2Vec” が Tomas Mikolov 氏のグループによって提案されました。この Doc2Vec は、文書(From Document)からベクトルへ(To
Vector)の変換モデルであり、(1)PV-DBOW、(2)PV-DM、の2種類のモデルから構成されます。
出展:Distributed Representations of Sentences and_Documents
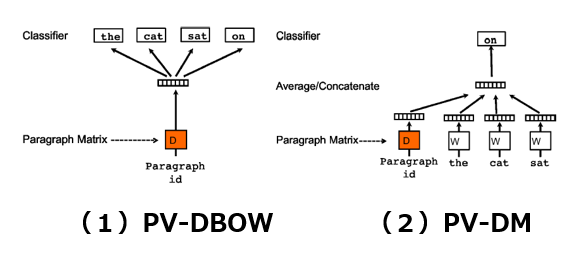
(1)PV-DBOW
“Distributed Bag of Words version of Paragraph Vector” の略。
ネットワーク構造が Skip-gram モデルに似ています。
(2)PV-DM
“Distributed Memory Model of Paragraph Vector” の略。
ネットワーク構造がCBOWモデルに似ています。
なお、 Doc2Vec は後ほど命名された通称であり、本論文中では、“Paragraph Vector” と呼んでいます。
以上、今回(第1回)は、Doc2Vec の概要について、Word2Vec との関係性を含めて説明しました。次回(第2回)は、PV-DBOWについて詳しく説明します。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。