
Doc2Vec(5/5)PV-DM<後編>
はぐれ弁理士 PA Tora-O です。前回(第4回)では、PV-DMモデルの概要について説明しました。改めて復習されたい方は、こちらのリンクから確認をお願いします。今回(第5回)は、学習方法に関する補足的な説明を行った上で、クレーム骨子を作成してみます。
PV-DMの学習方法
前回の記事(図2)で示したネットワーク構造に対して一から学習を開始しても一応問題ないのですが、これでは学習の効率が非常に悪くなります。そこで、PV-DMモデルでは、学習方法に工夫が施されています。PV-DMの “Distributed Memory” には、予め定めた単語の分散表現を記憶して学習に活用する、という意図があると考えられます。次の図1に、PV-DMの等価ネットワークを模式的に示しましょう。
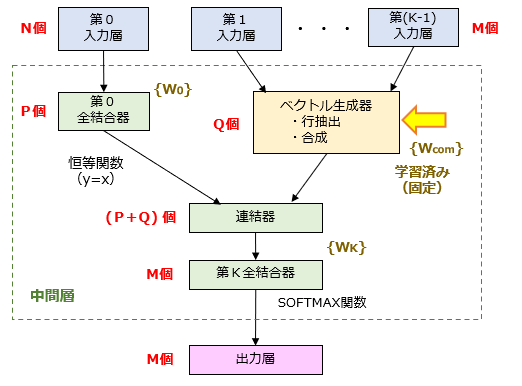
ここで、{Wcom}は、コーパス(Corpus)に登録された全体の段落及び単語に対して、Word2Vec などの既存の手法を用いて計算される結合重み行列です。学習の際は、{Wcom}を固定させておき、他の結合重み行列{W0},{WK}のみを更新させます。これにより、単語間の関係性を反映させた学習を実行可能となり、段落と単語の間の関係性(最終的には、段落間の関係性)を一層高い精度で定量化することができます。
包括的クレームの作成
以上のように、Doc2Vec を構成する2つのモデルについて説明しました。以下、PV-DMのネットワークが、基本モデル(PV-DBOW)を部分的に含んでいる構造的特徴に着目し、両方のモデルを包含するクレーム骨子を作成してみました。今回のクレーム案では、Doc2Vec の亜種モデルをなるべく包含するように表現しています。それでも何らかの穴があるとは思いますが。
【クレーム骨子】(Doc2Vec)
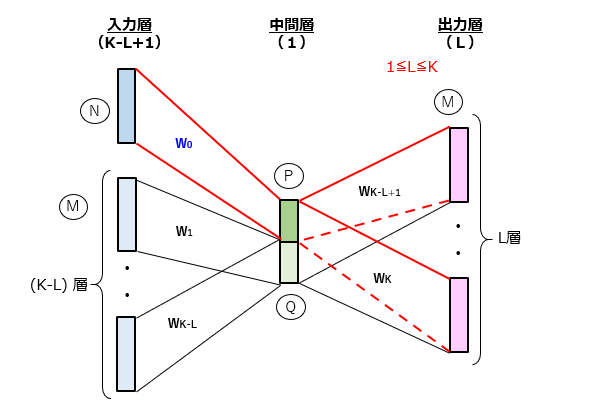
M個の単語のうちのいずれかを組み合わせたN個の単語列からなる単語列群の分散表現を行う方法であって、
[1]単語列のラベル集合を入力するN個の演算ユニットからなる1層の入力層、
[2]1≦P<Nの関係を満たすP個の演算ユニットを含む1層の中間層、および
[3]単語のラベル集合を出力するM個の演算ユニットからなるL層(1≦L≦K)の出力層
が全結合により順次接続された構造を含むニューラルネットワークを用いて、各々の単語列に含まれるK個の連続する単語同士の関係性を学習するステップと、
学習を通じて決定された入力層と中間層との間の結合重み行列から、連続値の成分を有するP次元のベクトルを単語列毎に求めるステップと、
を備えることを特徴とする分散表現方法。(314文字)
(注)PV-DBOWクレームに対する変更箇所を赤色太字で示しています。
以上をもちまして、Doc2Vec の事例検討を終了します。次回から、また別のテーマに移ります。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。