
Doc2Vec(3/5)PV-DBOW<後編>
はぐれ弁理士 PA Tora-O です。前回(第2回)では、PV-DBOWモデルの概要について説明しました。改めて復習されたい方は、こちらのリンクから確認をお願いします。今回(第3回)は、先に提示した疑問点を解消した上で、クレーム骨子を作成してみます。
PV-DBOW の学習方法
1つの段落がS個の単語で構成される場合、教示データの入出力関係が1対多、具体的には、1:(S-K+1)となるので、出力側の「正解」をどのように教示すればよいのかが問題になります。ここで、Kは、ウィンドウサイズと呼ばれる変数です。この場合の学習方法の模式図を示すと以下の通りになります。
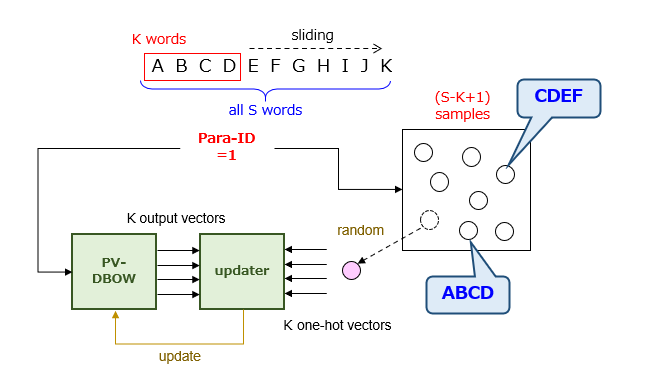
ざっくり言うと、段落IDが選択される度に、その段落から形成される(S-K+1)個の標本の中からランダム(つまり、等確率)に1個を選択して教示させます。この学習を通じて、PV-DBOWモデルは、段落IDの入力に対して、段落IDの母集団を構成する全標本の平均値を出力するようになります。この表現は技術的に厳密ではないかもしれませんが、感覚的に理解する上で十分であると思われます。
クレームの試作
以上、一通りの疑問が解消されたところで、PV-DBOWのクレーム骨子を作成してみます。幸いなことに、以前の事例検討(Word2Vec)の際に作成したクレームをそのまま活用できました。
参考: Word2Vec(4/4)クレーム骨子の作成
【クレーム骨子】(PV-DBOW)
M個の単語のうちのいずれかを組み合わせてなるN個の単語列からなる単語列群の分散表現を行う方法であって、
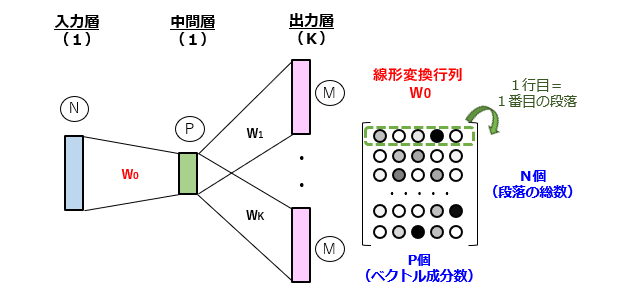
[1]単語列のラベル集合を入力するN個の演算ユニットからなる1層の入力層、
[2]1≦P<Nの関係を満たすP個の演算ユニットからなる1層の中間層、および
[3]単語のラベル集合を出力するM個の演算ユニットからなるK層の出力層
が全結合により順次接続されたニューラルネットワークを用いて、各々の単語列に含まれるK個の連続する単語同士の関係性を学習するステップと、
学習を通じて決定された入力層と中間層との間の結合重み行列から、連続値の成分を有するP次元のベクトルを単語列毎に求めるステップと、
を備えることを特徴とする分散表現方法。(311文字)
なお、「段落」には文章の塊という意味がありますので、クレームにそのまま使っても特に問題ない気がしますが、フルの文書の場合は含まれるのかどうか若干心配になりました。とりあえず「単語列」という表現で逃げましたが、より良い表現が見付かり次第、適宜修正します。
まとめ
PV-DBOWモデルでは、上記した学習を通じて結合重み行列を決定することで、段落の分散表現を獲得します。ただ、この手法では、段落と単語の間の関係性を学習しているにすぎず、単語間の関係性があまり考慮されていないように思えます。
そこで、“Doc2Vec“ の論文では、ベストモードとも言えるPV-DM(Distributed Memory Model of Paragraph Vector)が提案されています。次回(第4回)から、PV-DMについて詳しく説明します。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。