
ドロップアウト(1/4)発明の概要
はぐれ弁理士 PA Tora-O です。 今回のテーマとして、ディープラーニングで頻出のドロップアウトを題材に取り上げていきます。
背景
機械学習の1つの類型として、入力値と教示値(正解値)からなる訓練データを与えて学習を行う教師あり学習が挙げられます。この教師あり学習では、出力値と教示値の差分の関数である損失関数(ここでは、訓練誤差)が大局的最小値(Global Minimum)になる学習パラメータセットを求め、損失関数が最小値に近づくように学習パラメータセットを逐次更新していきます。この学習パラメータは、例えば、演算ユニット同士を連結する結合重みや、活性化関数の閾値(バイアス)に相当します。
問題の所在
ところが、学習器が訓練データに対して過剰に適合した結果、学習が適正に完了したにもかかわらず、未知のテストデータに対して思ったほどの推定精度が得られない現象が起こり得ます。このように、訓練誤差とテスト誤差の間に乖離を生じさせるこの現象は、過学習(overfitting)と呼ばれています。
解決手段
そこで、上記した問題を解決すべく、ドロップアウトという技術が提案されました。この技術は、ILSVRC2012のコンペティションで優勝した「AlexNet」にも実装されており、Krizhevsky et al.の論文(2012) の中でも言及されています。 端的に言えば、「中間層の中からランダムに選択した一部の演算ユニットを学習に用いて、残りの演算ユニットを学習に用いない」ことが特徴です。この手法を図で表現すると、以下のようになります。
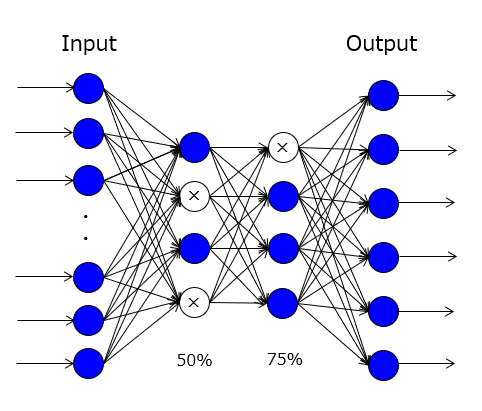
【図】ドロップアウトの模式図
図中の塗り潰しがない3個の丸印は、ドロップアウトされた演算ユニットに相当します。ちなみに、活性化率がp(0<p≦1)である場合、結合重みが1/p倍に強化された状態で学習がなされるので、推論フェーズでは、この強化を相殺するために、演算ユニットの出力値または結合重みをp倍する操作が必要になります。
このドロップアウトによって、複数の学習器を用いた予測結果を統合して汎化性能を高める「アンサンブル学習」と同種の効果、いわゆるロバスト性の向上効果が得られます。ただ、実際に準備する学習器が1個であるため、より正確にはアンサンブル学習の亜種と呼んだ方がよいかもしれません。
以上、今回(第1回)は、ドロップアウトについて、その背景を含めて説明しました。この技術をさらに詳しく知りたい方は、例えば、「ニューラルネット」&「ドロップアウト」で検索してください。
次回(第2回)は、ドロップアウトの実施例について検討していきます。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。