
YOLO(3/4)OverFeat との対比
はぐれ弁理士 PA Tora-O です。前回(第2回)では、YOLOの実施例について説明しました。改めて復習されたい方は、こちらのリンクから確認をお願いします。今回(第3回)は、One-stage Detector の先行技術である “OverFeat” の紹介と、技術的な相違点について解説します。
OverFeat の概要
OverFeat は、Pierre Sermanet 氏ら(Yann LeCun 氏の研究グループ)により提案されたモデルです。図1に示すように、このモデルは、8層のレイヤから構成されています。なお、図中の “conv” は畳み込み層、”max” は最大プーリング層、“full” は全結合層を示しています。
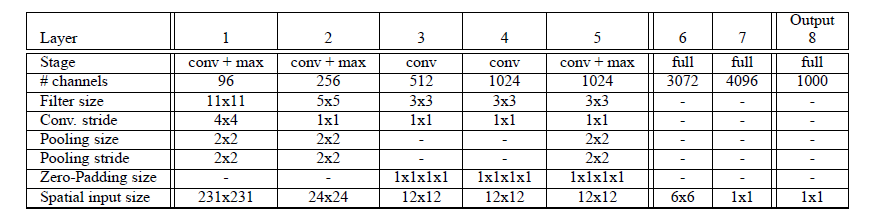
出展:OverFeat:Integrated Recognition, Localization and Detection using Convolutional Networks
図1だけを見ると、物体の種類及び位置が出力層から同時に出力されるように理解しがちです。しかし、実際には、OverFeat は、抽出器(レイヤ1~5)で抽出された特徴マップを共用しつつ、別々の推定器(レイヤ6~8)を用いて、物体の種類および位置をそれぞれ推定します。
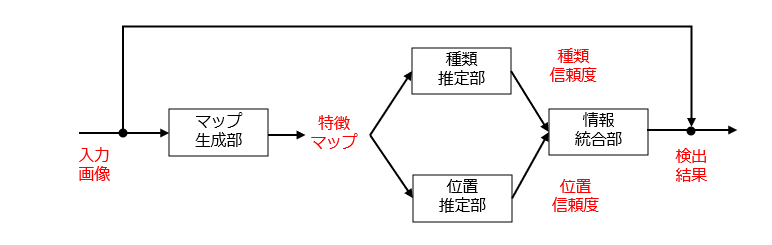
ちなみに、OverFeat では、入力画像(特徴マップ)の画素を1個ずつずらしながら入力し、得られた特徴マップを補間することで、特徴マップの疑似的な高解像度化を実現する “sliding window approach” が導入されています。ここでは、具体的な説明を割愛します。
YOLOの特徴
一方、YOLOの機能ブロックは、図3のようになります。
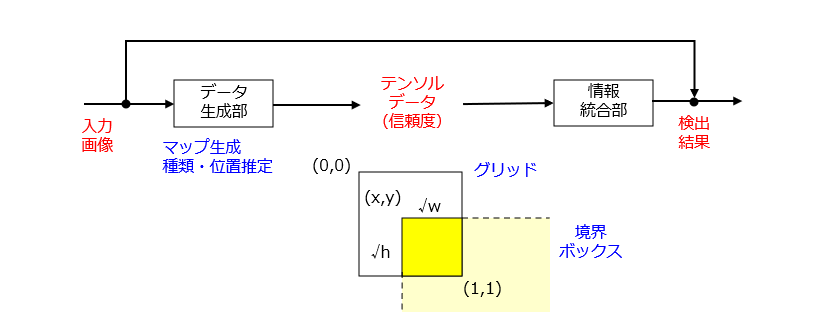
図2との比較から理解されるように、YOLOは、[1]特徴マップの生成、[2]物体種類の推定、[3]物体位置の推定、の3つの機能を同時に実行する単体のニューラルネットワークからなります。それでは、何故、3つの機能を1つのネットワークに統合できたのでしょうか? その答えは、出力データの設計の工夫、特に、境界ボックスの表現方法にあると思われます。
入力画像の全体領域をグリッド化(複数のサブ領域に分割)するという発想はよくあるのですが、境界ボックスの位置、ここではボックスの占有範囲をグリッド毎の相対座標系で表現するという発想は新規であると思われます。これにより、物体の種類および位置に関する信頼度付きの推定結果をグリッド毎にまとめたテンソルデータとして統合することができます。そして、隣り合うグリッド同士の推定結果を突き合わせて、境界ボックスまたは物体の異同を判定すればよい、という訳です。
どうやら、ここにYOLOの特徴がありそうです。しかも、YOLOのネットワーク構造に限られず、様々なモデルにも応用できそうな技術とも言えます。
以上、今回(第3回)は、OverFeat との対比を行いつつ、YOLOの技術的特徴について解説しました。テーマ最終回(第4回)は、過去3回分の総括として、一連の発明ストーリーを作成します。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。