
Seq2Seq(2/4)再帰型ニューラルネット
はぐれ弁理士 PA Tora-O です。前回(第1回)では、Seq2Seq の概要について説明しました。改めて復習されたい方は、こちらのリンクから確認をお願いします。今回(第2回)は、Seq2Seq を理解する上での前提知識ともいえる再帰型ニューラルネットワーク(RNN;Recurrent Neural Network)の概要について説明します。
問題の設定
RNNでは、指定された文章を1語ずつ暗唱する、暗唱問題について取り組みます(図1)。
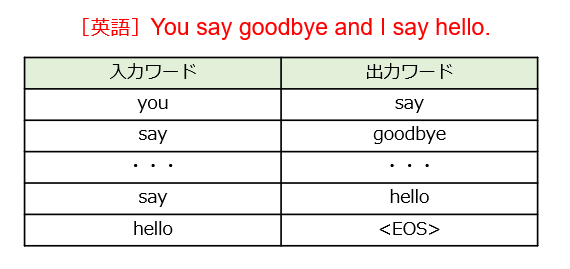
ここでは、人間による実際の暗唱とは異なり、[1]1番目の単語(you)を入力して2番目の単語(say)を出力し、[2]2番目の単語(say)を入力して3番目の単語(goodbye)を出力する、[3]・・・というタスクを時系列に実行することで、1つの文章を完成させていきます。ここでは、データベース(あるいはコーパス)に登録されているすべての単語(N個)の中から、1個ずつ選択されることにします。ちなみに、EOS(End Of Sequence)は、文章の終了を示す識別子です。
ネットワーク構造
続いて、上記した暗唱問題を解答させるRNNのネットワーク構造を図2に示します。
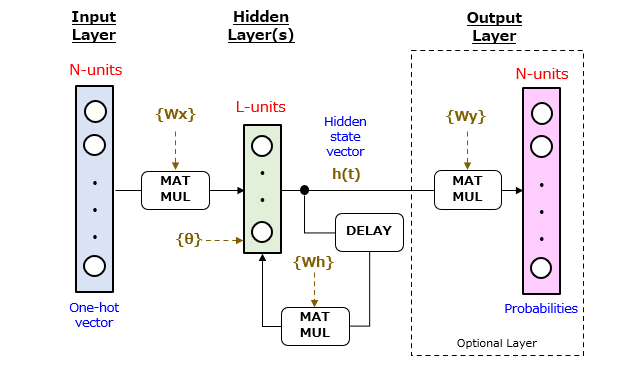
RNNは、入力層、隠れ層(中間層)、および出力層が順次接続されてなるニューラルネットワークです。RNNの特徴は、各々の隠れ層に再帰的なループ構造が設けられている点にあります。隠れ層の層数は、図2のように1層のみであってもよいし、2層以上あっても構いません。なお、隠れ層から出力されるL次元のベクトルh(t) は、隠れ状態ベクトル(Hidden State Vector)と呼ばれています。
続いて、演算子について説明します。「MATMUL」は、行列同士の積を求める行列積算器に相当します。入力側の演算子は、(1×N)と(N×L)の行列積からL次元ベクトルを求めます。中央側の演算子は、(1×L)と(L×L)の行列積からL次元ベクトルを求めます。出力側の演算子は、(1×L)と(L×N)の行列積からN次元ベクトルを求めます。また、「DELAY」は、1ステップ分の演算時間を遅延させて出力する遅延器に相当します。
続いて、学習パラメータについて説明します。機械学習を通じて更新される学習パラメータは、以下の4種類で構成されます。
{Wx}:入力層と隠れ層の間における結合重み係数(N・L個)
{Wh}:隠れ層の演算ユニット同士を接続する結合重み係数(L・L個)
{Wy}:隠れ層と出力層の間における結合重み係数(N・L個)
{θ} :活性化関数のバイアス(L個)
ここで、隠れ層の層数がKである場合、学習パラメータの総数#Pは、
#P=2NL+KL(L+1)
となります。次元削減(Dimensionality Reduction)を考慮すると、通常はL≪Nを満たすので、第1項の方が第2項よりも圧倒的に大きい数になっている筈です。
RNNの欠点と改良モデル
このように、RNNでは、活性化関数の合成演算および線形和演算を繰り返すことで、単語の配列関係(コンテキスト)を表現することができます。つまり、活性化関数の再帰的な呼び出しを通じて隠れ状態ベクトルが段階的に作成されることで、文字の配列を示す時系列情報が最終的な出力ベクトルに何らかの形で反映される、と解釈してもよいでしょう。この点は、畳み込みニューラルネット(CNN)における「空間情報と特徴マップの間の関係」に近いものがあります。
<参考:全体平均プーリング(3/5)特許性の検討>
ところが、RNNでは、先出した単語のみとの関係から隠れ状態ベクトルを次々と作成・更新するので、上記したコンテキスト(特に、離れた単語間の関係)を精度よく学習・再現できない場合があります。そこで、制御パラメータを追加してRNNの概念を拡張した新しいモデル、LSTM(Long Short-Term Memory)やGRU(Gated Recurrent Unit)が登場しました。今回の事例検討では、RNNの挙動を理解していれば十分ですので、上記した改良モデルの説明を省略します。
以上、今回(第2回)は、RNNモデルについて重要なポイントのみを説明しました。次回(第3回)は、Seq2Seq の実施例について説明します。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。