
StackGAN(1/4)発明の概要
はぐれ弁理士 PA Tora-O です。今回のテーマとして、敵対的生成ネットワーク(GAN)ベースのデータ変換処理の一手法である StackGAN を題材に取り上げます。
背景
生成モデルのバリエーション(Variants)の1つとして、テキスト文章の内容に沿った画像を生成する “Text-to-Image Transfer” が挙げられます。先行技術として、例えば、Scott Reed 氏らによる GAN-INT-CLS があります。
出展:Generative Adversarial Text to Image Synthesis
この GAN-INT-CLS は、[1]損失関数の改良(GAN-INT)、[2]学習アルゴリズムの改良(GAN-CLS)を組み合わせた手法です。今回は、これらの特徴事項には触れずに、ネットワーク構造のみを説明します。
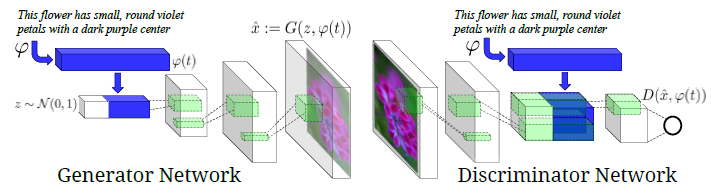
注目すべきは、やはり本モデルもCGAN(Conditional GAN)を踏襲している点です。あと、テキスト文章を符号化した後のテキスト特徴量(青色で図示)の入力方法にも特徴があります。生成器(Generator)の場合では、テキスト特徴量は、ノイズベクトルと連結させた状態で入力されます。一方、弁別器(Discriminator)の場合では、テキスト特徴量は、畳み込みニューラルネットワーク(CNN)で得られた画像特徴量と連結させた状態で入力されます。
問題の所在
ところで、画像は、多値(8ビットの場合は、256通り)の中から選択し得る画素値を有する多数の画素(例えば、100×100画素)からなるデータであり、場合によっては複数のカラーチャンネル(RGB)をもっています。すなわち、“Text-to-Image Transfer” において、変換後の画像データは、変換前のテキストデータと比べて圧倒的に情報量が多いと言えます。この場合、生成器の学習能力に限界があって高解像度の画像を生成することができない、という問題がありました。
解決手段
そこで、GANをstackしたモデルである StackGAN が Han Zhang 氏らによって提案されました。まずは、生成後の画像を比較してみます。

図2の「上段」がテキスト文章、「中段」が GAN-INT-CLS による画像、「下段」が StackGAN による画像をそれぞれ示しています。例えば、最も左側の画像は、次のテキスト文章から生成されました。
This flower has a lot of small purple petals in a dome-like configuration
(この花は、ドーム状の構成で小さな紫色の花びらが沢山あります)

図2のサイズでは両者の違いが分かりにくいと思いますので、もう少しだけ画像を拡大してみます。このように、StackGAN の導入によって高解像度の画像を生成することができました。
以上、今回(第1回)は、StackGAN の概要について説明しました。次回(第2回)は、StackGAN の実施例について説明します。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。